Python爬虫:爬取B站视频 小白教学(解决b站视频与音频分离问题,超级详细保姆级教学)_b站视频爬取
1. 完整的代码
url和cookie是我之前做的但不影响,对号入座就行,你们这么聪明我相信你一定会的
import osimport reimport jsonimport requestsimport subprocessfrom urllib.parse import quotedef sanitize_filename(title): \"\"\"清理文件名中的非法字符\"\"\" return \"\".join([c if c.isalnum() or c in (\' \', \'_\', \'-\') else \'_\' for c in title])def download_file(url, path, headers): \"\"\"带进度显示的文件下载函数\"\"\" with requests.get(url, headers=headers, stream=True) as r: r.raise_for_status() total_size = int(r.headers.get(\'content-length\', 0)) downloaded = 0 with open(path, \'wb\') as f: for chunk in r.iter_content(chunk_size=8192): f.write(chunk) downloaded += len(chunk) if total_size > 0: print(f\"\\r下载进度: {downloaded/total_size:.1%}\", end=\'\') print(f\"\\n文件已保存到: {os.path.abspath(path)}\")def main(): # 配置参数(*需要修改,根据自己的URL修改) url = \'https://www.bilibili.com/video/BV13g4y1M7TX/\' # 配置cookie(*需要修改,根据自己的cookie修改) cookie = \"buvid_fp_plain=undefined; enable_web_push=DISABLE; header_theme_version=CLOSE; DedeUserID=3494371622128053; DedeUserID__ckMd5=c6993685b1d95f4b; buvid4=A462A970-0561-1CD9-DE92-2B231FEEBD6097247-023100717-r1tmH8aidYxmm%2BqtUn3sHA%3D%3D; PVID=1; fingerprint=4a836e9691cfd18f9cf53b86ab20e74f; buvid_fp=4a836e9691cfd18f9cf53b86ab20e74f; _uuid=D2D49D91-26B2-E8E7-41A3-9AD5E5FBF84C79447infoc; buvid3=0C50FB06-4A36-BBF9-B911-CD066CE1FC3467335infoc; b_nut=1731243767; rpdid=|(um~RuJ~RJR0J\'u~JukRJ~Ym; home_feed_column=4; CURRENT_QUALITY=80; b_lsid=86104610AD_1969B199490; bsource=search_bing; enable_feed_channel=ENABLE; browser_resolution=1133-627; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NDY2MTgzMzAsImlhdCI6MTc0NjM1OTA3MCwicGx0IjotMX0.cHLpgPhNjHIGrH0cgItCpcSqia-qsnL1allKOU-5FeI; bili_ticket_expires=1746618270; SESSDATA=423cd741%2C1761911154%2C36bc4%2A52CjCiFE0Uq40s5r61fUN0fbcXC-EupUSs7TCjtUgmHnIOXAxLFEhadfxXKxzQFJow7eYSVlZRb1AtX3J6U0ZaWXh5dFhjX0ZHTEdMSEZmc1dqbzFzblVCczhwRzZ4NXgzb0l1MlRPMWdsY0xQbi01X2hLNnVOaUNEZEVYRjJxcFNkVU9kWDFRS2lRIIEC; bili_jct=fdf9c252fcc731f14f61b178301a6f4c; sid=6lgfjhmf; bp_t_offset_3494371622128053=1063103039683952640; CURRENT_FNVAL=4048\" # 请求头配置 headers = { \"Referer\": url, \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36\", \"Cookie\": cookie, \"Origin\": \"https://www.bilibili.com\" } try: print(\"正在获取页面信息...\") response = requests.get(url=url, headers=headers) response.raise_for_status() html = response.text # 提取视频标题 title = re.findall(\'(.*?)_哔哩哔哩_bilibili \', html)[0] safe_title = sanitize_filename(title) print(f\"视频标题: {title}\") # 提取视频信息 play_info = re.findall(\'window.__playinfo__=(.*?)\', html)[0] json_data = json.loads(play_info) # 获取音视频URL video_url = json_data[\'data\'][\'dash\'][\'video\'][0][\'baseUrl\'] audio_url = json_data[\'data\'][\'dash\'][\'audio\'][0][\'baseUrl\'] # 视频下载头需要Range参数 video_headers = headers.copy() video_headers[\"Range\"] = \"bytes=0-\" # 创建临时目录 os.makedirs(\"temp\", exist_ok=True) # 下载视频和音频 print(\"\\n正在下载视频流...\") video_path = os.path.join(\"temp\", \"video_temp.m4s\") download_file(video_url, video_path, video_headers) print(\"\\n正在下载音频流...\") audio_path = os.path.join(\"temp\", \"audio_temp.m4s\") download_file(audio_url, audio_path, headers) # 根据实际安装路径修改(很重要) FFMPEG_PATH = r\"D:\\小程序\\ffmpeg-2025-05-01-git-707c04fe06-full_build\\ffmpeg-2025-05-01-git-707c04fe06-full_build\\bin\\ffmpeg.exe\" # 合并音视频 print(\"\\n正在合并音视频...\") output_path = f\"{safe_title}.mp4\" ffmpeg_cmd = [ FFMPEG_PATH, # 使用绝对路径 \'-i\', video_path, \'-i\', audio_path, \'-c:v\', \'copy\', \'-c:a\', \'aac\', \'-movflags\', \'+faststart\', \'-y\', output_path] subprocess.run(ffmpeg_cmd, check=True) print(f\"\\n合并完成!最终文件: {os.path.abspath(output_path)}\") except requests.exceptions.RequestException as e: print(f\"网络请求失败: {e}\") except json.JSONDecodeError as e: print(f\"JSON解析失败: {e}\") except subprocess.CalledProcessError as e: print(f\"FFmpeg合并失败: {e}\") except Exception as e: print(f\"发生未知错误: {e}\") finally: # 清理临时文件 if os.path.exists(video_path): os.remove(video_path) if os.path.exists(audio_path): os.remove(audio_path) print(\"临时文件已清理\")if __name__ == \"__main__\": main()2. 爬取b站视频
2.1 网页搜索b站(如果是在APP上无法爬取)
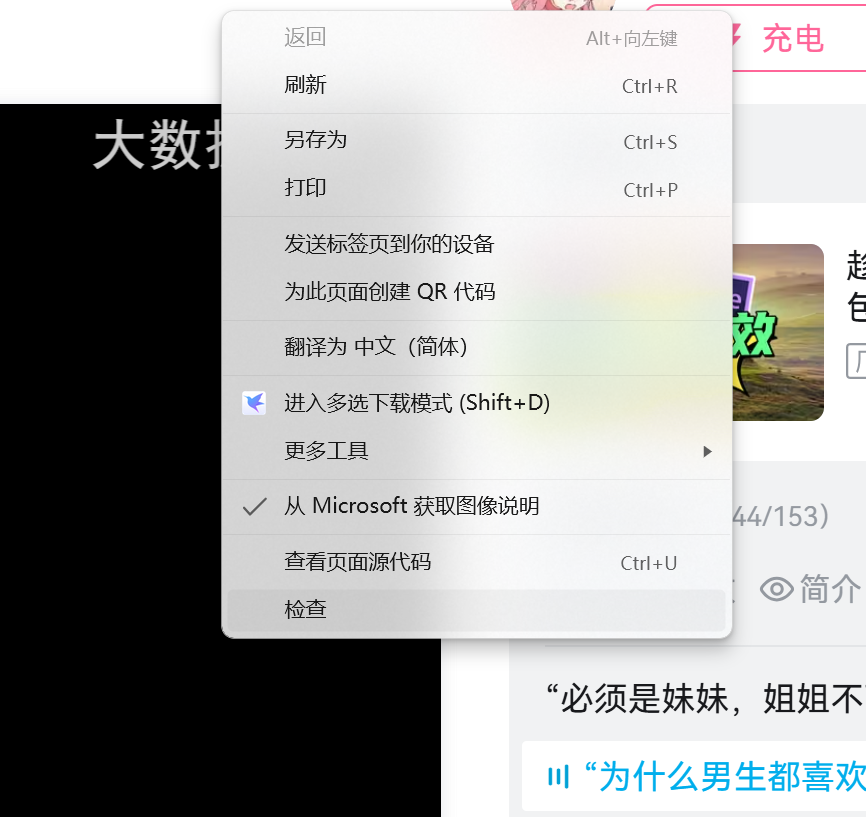
2.2 检查(点击)
2.3点击工具上方的网络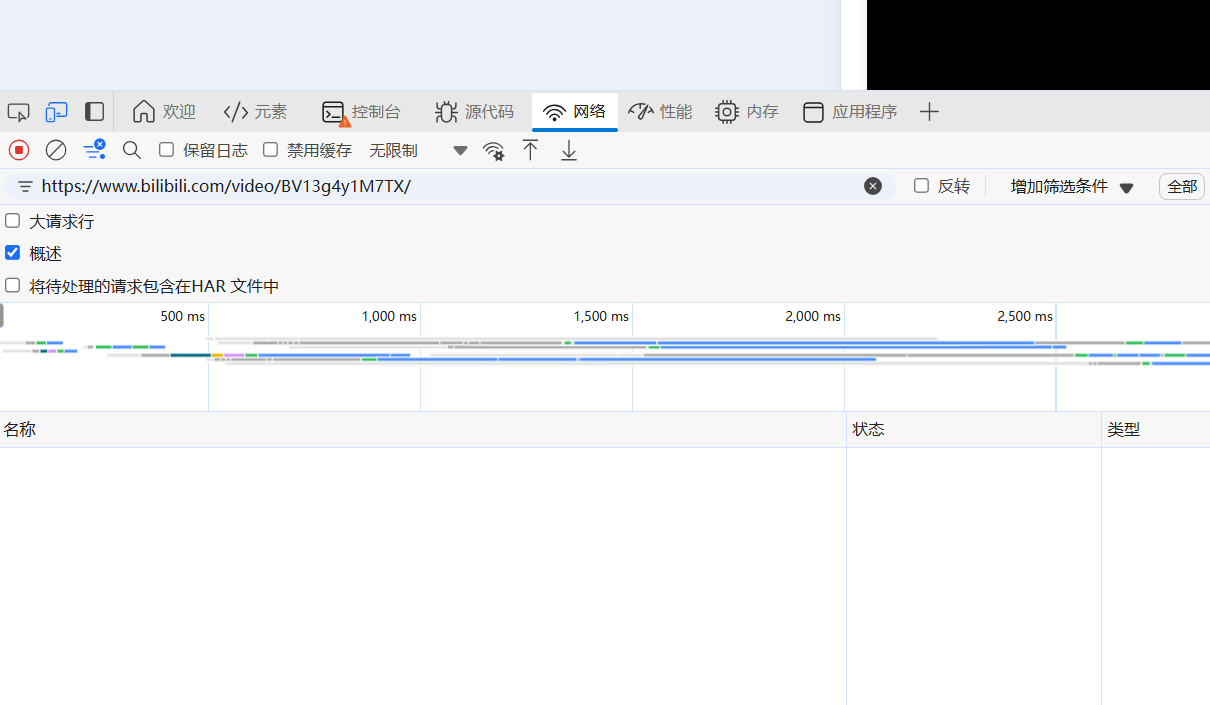
2.4 回车(重新刷新)
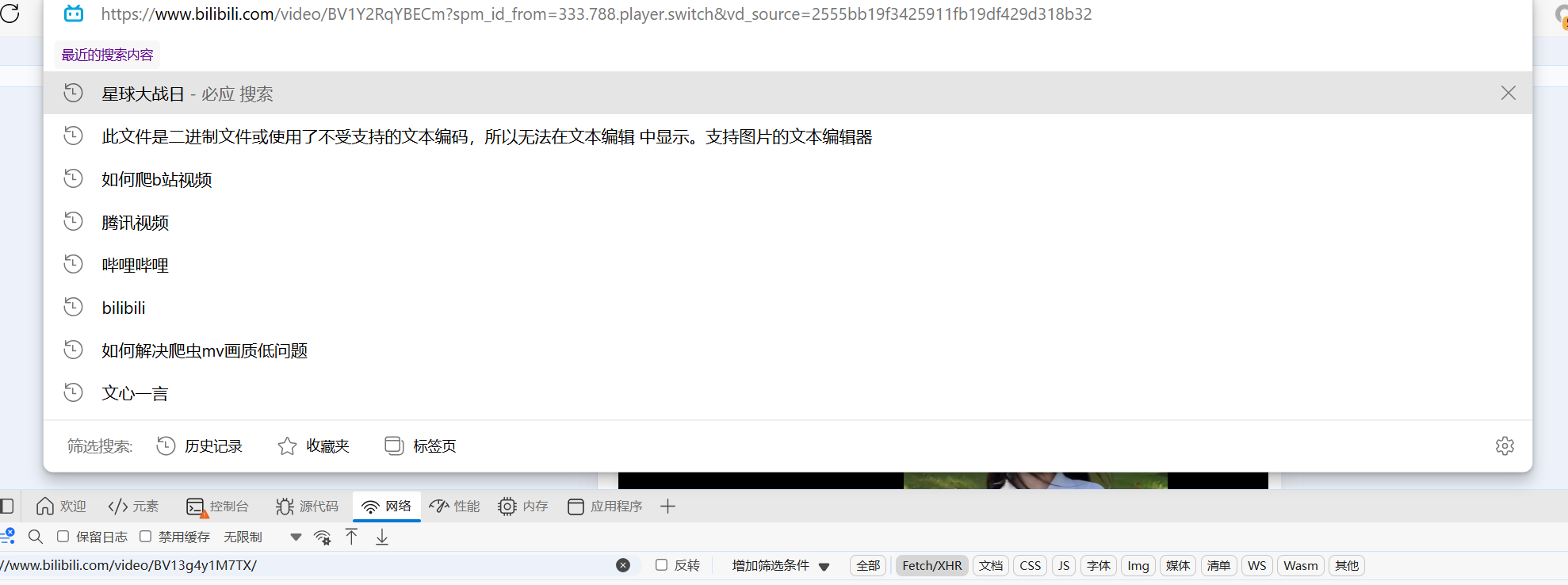
2.5 通过搜索工具(就是网页上的http)
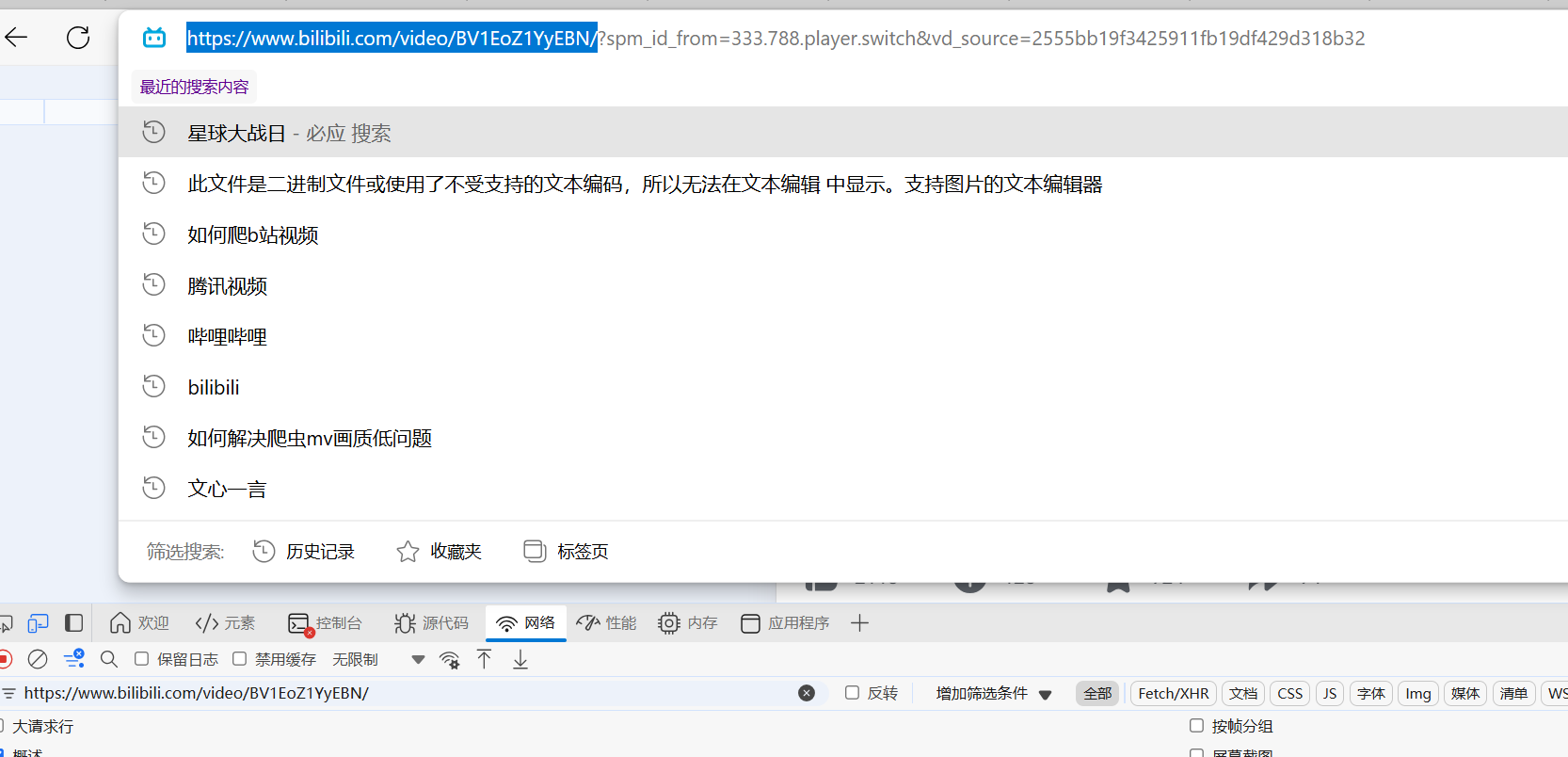
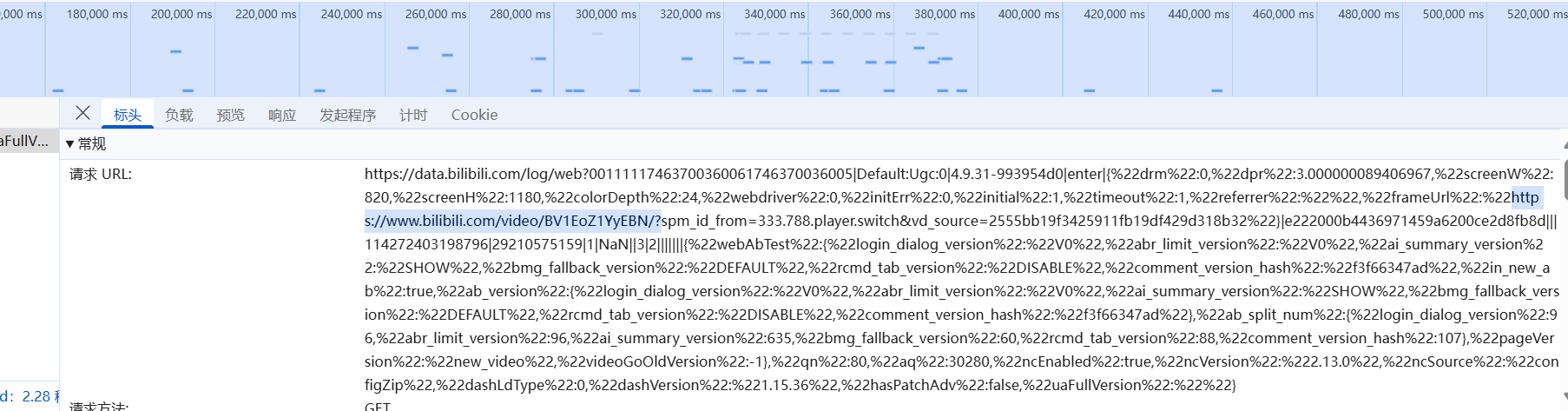
2.6 获取请求url(只要标蓝的部分,因为b站有加密机制,不能完全复制**那部分其实就是搜索的部分)
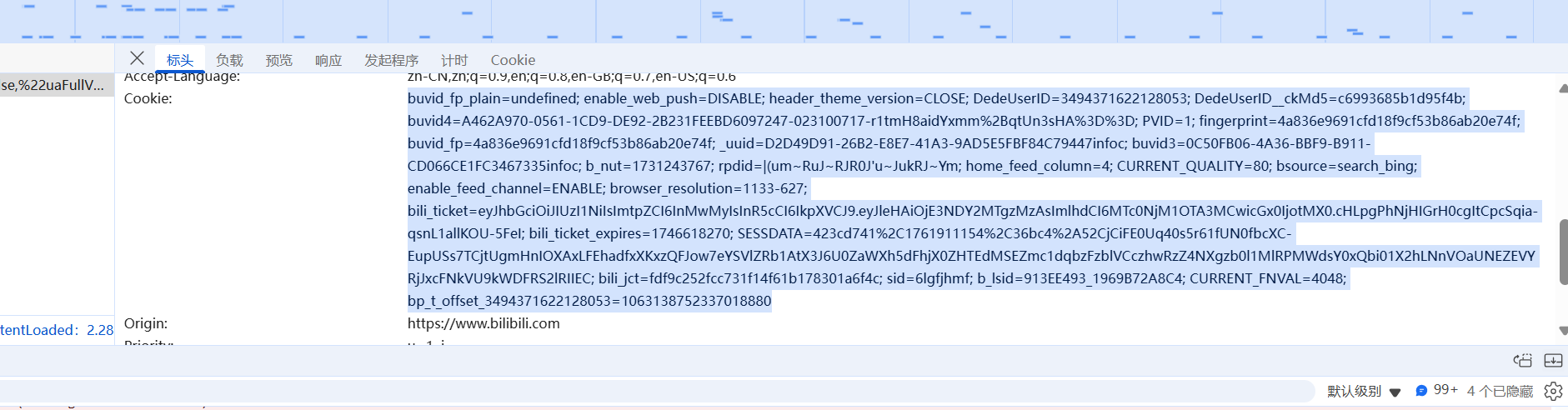
2.7 找到cookie(全部粘贴复制)
3. 环境配置
3.1 安装FFmpeg(必须步骤)//如果没有配置FFmpeg
3.1.1 下载FFmpeg:https://www.gyan.dev/ffmpeg/builds/
3.1.2 解压zip文件到 C:\\ffmpeg (自己可选择)
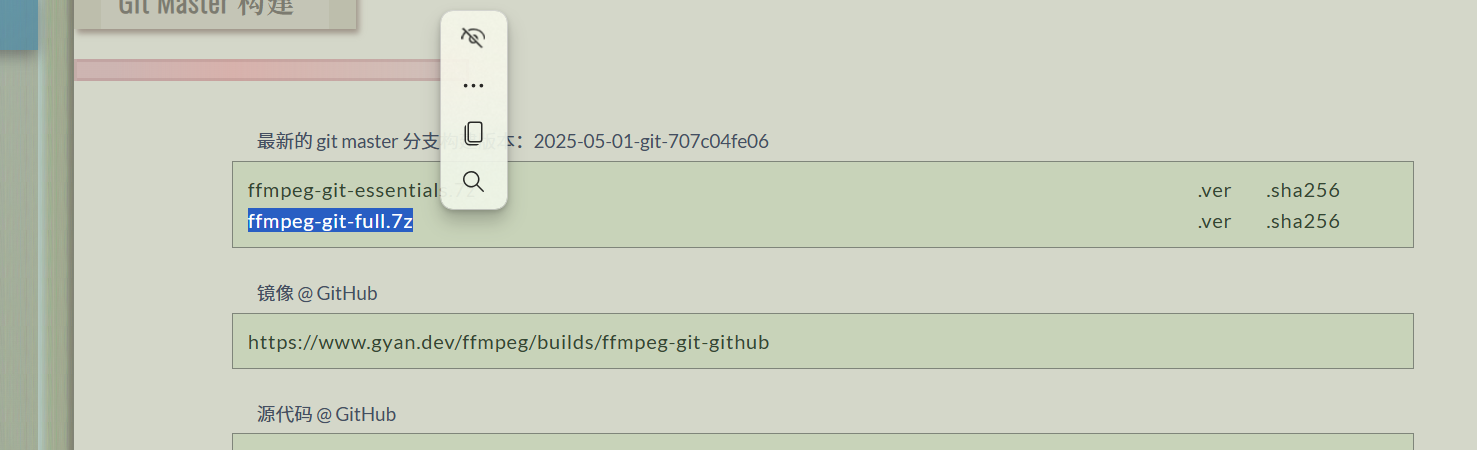
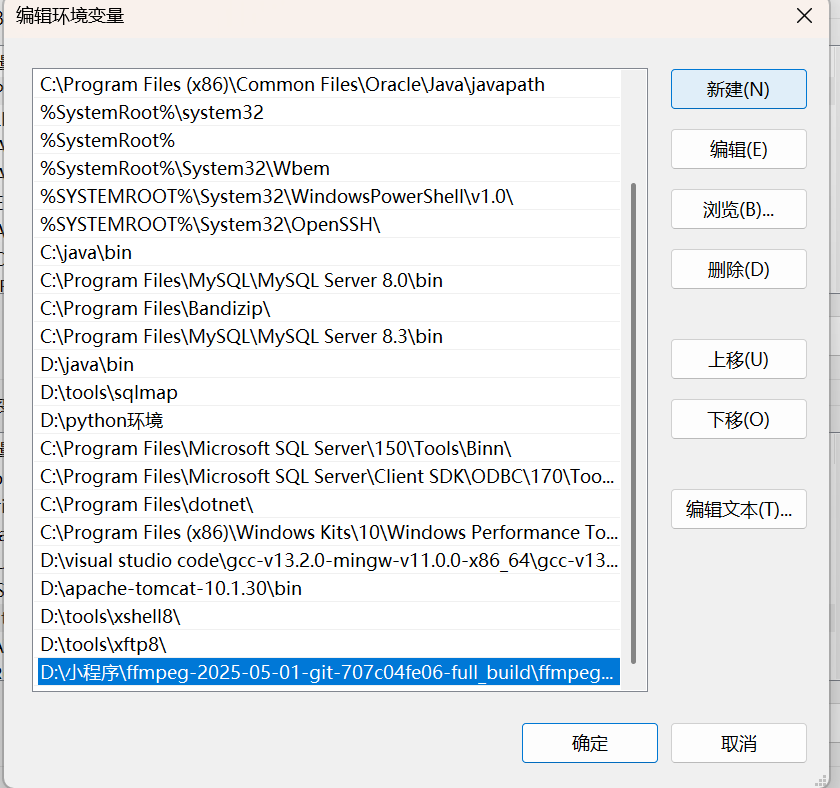
3.1.3 添加系统环境变量:
-
右键\"此电脑\" → 属性 → 高级系统设置 → 环境变量
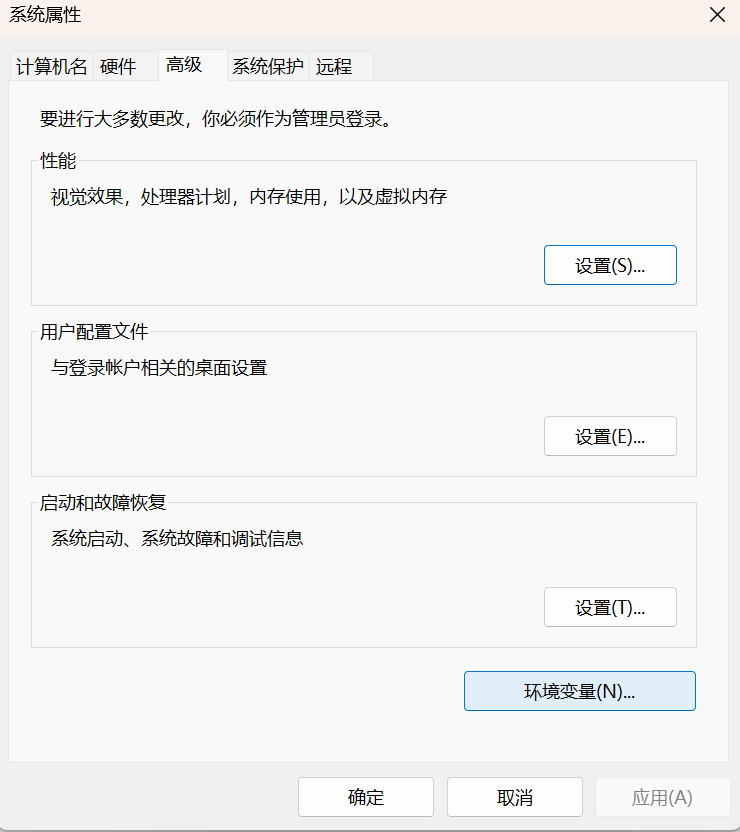
-
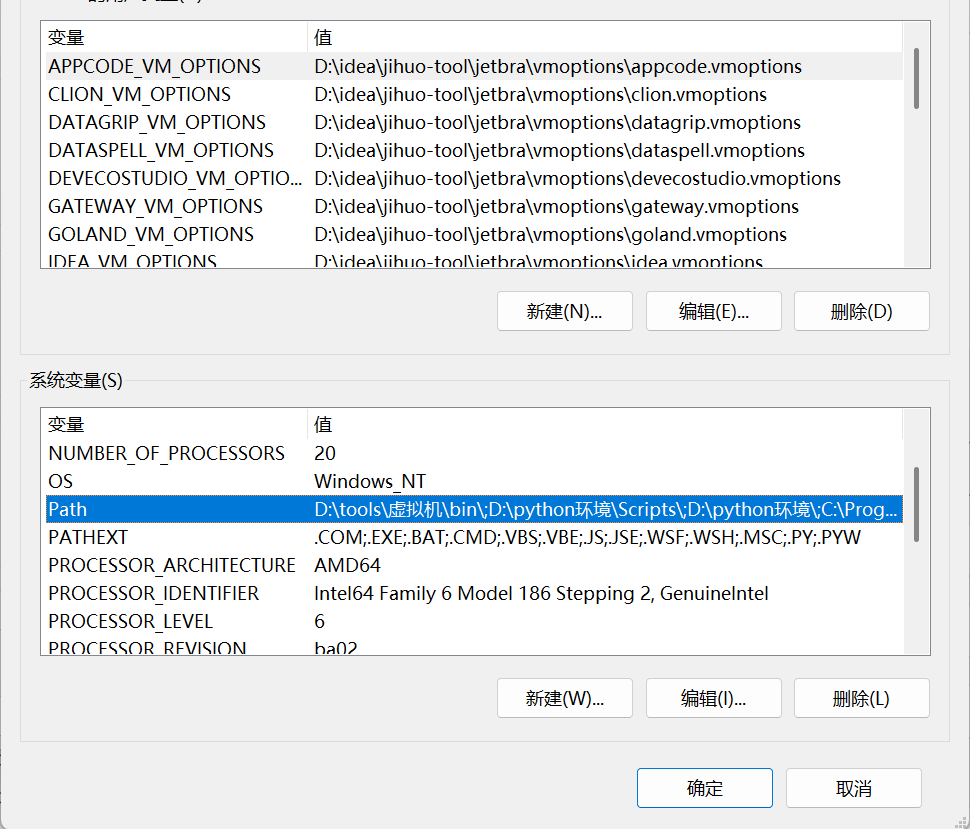
在
Path中添加:C:\\ffmpeg\\bin(在bin目录下)
4.万能b站爬虫就成功了
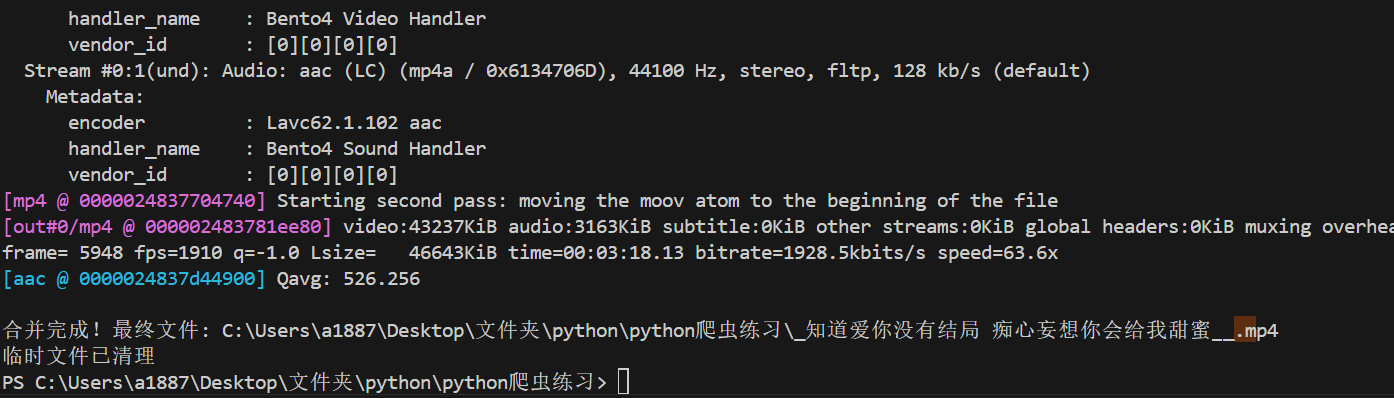
4.1python中运行后的结果
4.2打开文件看看吧(OK,小姐姐出来了)
你学会了吗(第一次发博客请大家多多关照,制作不易,给个小心心吧!)

