音频指纹识别_音频识别
概要
每一个个体都是独一无二的,这对于音频也是适用的。音频指纹技术是指通过特定的算法将一段音频中提取出独一无二的数字特征,广泛应用于音乐识别,版权内容监播,内容库去重和电视第二屏互动等地方。
一般来说,算法要求识别过程不受音频本身的储存格式,编码方式,码率和压缩技术影响。而且一般不会对文件添加数据如水印之类的。
网易音乐,qq音乐中都有一个功能,可以通过听取一段音乐来识别这是哪一首歌曲。这也都是音频指纹技术实现的。
因为以Shazam为代表的歌曲识别应用已经非常成熟,静态数量的歌曲识别以Shazam为代表的程序已经做得很好了,本文的应用场景并不是要重新实现Shazam的算法,而是以流式音频/动态音频(比如说电台/电视台播放的视频)或者音频数量有限的场景,抽取的指纹数据存放在文件/内存中,算法在这些动态变化的音频数据中搜索目标音频。
特征
只提供内存匹配功能,要存在数据库的可以用Shazam。
支持动态的流式目标音频的特征提取服务,目标场景是在多路流式待匹配音频中检测是否含有待匹配内容。(比如说数百路流式电视,电台音频信号)。
支持多路并发的特征提取和匹配服务。
基于c/c++实现,算法检测速度快,效率高。
应用场景
- 音乐识别
应该说音频指纹技术最早就是为听歌识曲功能开发的。当用户听到一段喜爱的旋律却不知道歌名的情况下,用户只需用手机录一段听到的歌曲片段,即可通过音频指纹检索的方式获知到歌曲的名称。以Shazam为代表的歌曲识别应用是最早开发和应用音频指纹技术的公司,现在国内大多数音乐软件也基本内含音乐识别功能。
- 电视第二屏互动
手机APP通过运用音频指纹技术的识别,仅需几秒钟的录音即可识别当前播放的频道和节目进度,从而方便应用开发者制作出与节目相关的互动和应用。国外社交,追剧,和电影衍生品应用比如Facebook,Shazam, Viggle, Thetake等均加入了电视识别的功能。国内微信摇电视,手机淘宝首页摇一摇,扫购神器,剧淘,扫购神器,悦赢等应用也均通过音频识别的方式提供电视互动和边看边买的T2O服务。
- 音乐、广告监播
音频指纹技术可监测电台,电视台中使用的内容的播放时间,播放次数和播放时长。广泛的被音乐版权公司和广告商投放商应用于监测广告和音乐在媒体中播放的数据。如:歌手如果需要开演唱会,可通过全国电台电视台的监测数据,获知哪些电台和电视台在最近有播过他的哪些歌曲,进而确定演唱会的地点和歌曲。广告商投放者和代理商可通过音频指纹技术的监测来获知电视台电台是否在规定的时间播放其投放的广告,播放时长是否符合要求。同时也可以通过监测获知竞品的广告投放信息。
- 版权检测与内容判重
监控网络平台,确保音频内容的原创性,防止盗版。
通过音频指纹的识别,可获知数字媒体文件中是否含有相同的内容。全球知名网站Youtube和Facebook都是通过音频指纹技术建立的Content ID系统将受版权保护的内容指纹与用户新上传的内容进行匹配,可快速检索是否含有侵权内容。广电媒资系统可通过音频指纹的匹配获知媒体库中哪些内容是重复和关联的。
- 收视调查
基于音频指纹的收视调查已经作为电视收视率调研的一种新的方式应用于一些国家。美国公司Symphony和蒙古公司MIT通过基于音频指纹技术的sdk预制到手机应用中,通过手机的录音功能获知用户看电视的收视习惯。很多机顶盒和智能电视服务商如三星,LG和Vizio也将此技术预置于系统中,收集用户的收视习惯和广告推荐。
- 视频内容分析
在社交媒体分析中,用于追踪特定声音片段的传播和影响。
- 个性化推荐
这种特征提取和匹配技术也为个性化音乐推荐提供了基础。推荐系统通过深度学习分析音乐的情感、风格判断歌曲的情绪(如欢快、悲伤、激动)、根据音乐的旋律、节奏、情感等特征来挖掘用户的喜好,不仅提高推荐的准确性,而且能为用户发现更多与其品味相符的音乐。
- 音乐流派分析
另外音乐指纹还可以检测音乐中的采样和相似度,甚至可以用于找出某些流派的起源和灵感来源。
算法原理
最常用的指纹提取算法是shazam公司03年发表的论文《An Industrial-Strength Audio Search Algorithm》提出的landmark算法,由于landmark算法的检索准确率较高,即使音频片段中包含很强的噪音和扰动,并且经过各种损害性处理,例如压缩和网络丢包等,算法也需要准确地返回结果。因而该算法获得了广泛的研究和应用。很多音乐指纹算法或多或少的与该算法有关
音频指纹的提取过程:
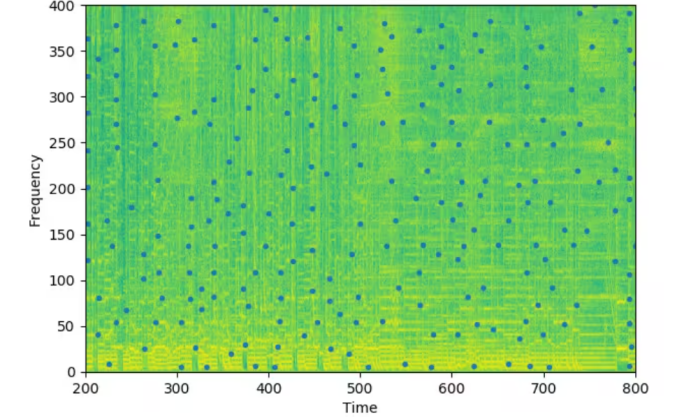
- 首先找出音频中能量较大的关键点或特征点。这些关键点在音频处理中具有重要的意义,因为它们不容易受到噪音或其他干扰的影响,从而提高了音频指纹的鲁棒性。
- 然后对不同的频率范围会被分别处理,这样能够确保对低音、中音和高音的均衡分析,避免混淆或漏掉某些音乐元素。
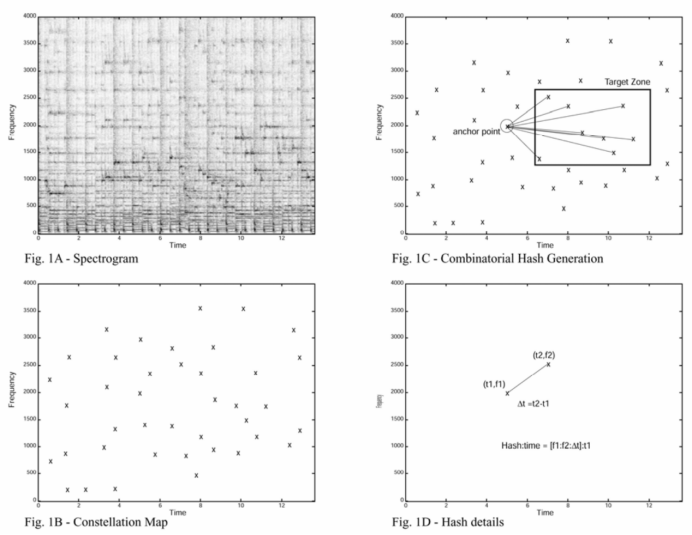
- 计算指纹:选择一个锚点,并将锚点与目标区域内所有高能量点进行组合,得到一个包含两个频率(f1, f2)和一个时间差(△t)的音频指纹。这个音频指纹也可以被计算成一个哈希值,方便快速搜索,也可以不计算。
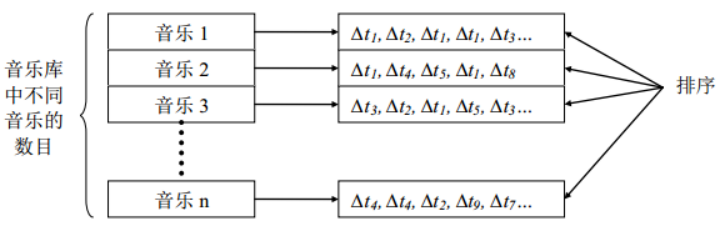
- 数据组织:所有的音频指纹被组织成一张称为倒排索引结构的表,意思就是通过这张表可以由音频指纹去搜索相应的音乐。每一个指纹都指向一个音乐文件id和时间pos的结构。
音频中能量较大的关键点或特征点:
论文所示的指纹提取过程:
指纹的倒排索引表:

音频指纹的识别过程:
匹配过程:
- 对一个目标音频先提取指纹,得到一个(f1, f2, △t)的列表。
- 对列表中的每一个指纹都查找倒排索引表,获得该指纹对应的倒排列表(一个(id, pos)的列表)
- 将倒排列表中每一个音乐对应的时间和提取的指纹对应的时间进行相减,如果时间差大于零,则保存该时间差到一个目标音乐列表中(一个由音乐-时间差列表组成的列表)
- 对每首歌中的时间差进行排序;
- 统计每首歌中时间差相同的个数,并返回个数最多的音乐。
匹配过程就是记录这样一张表:
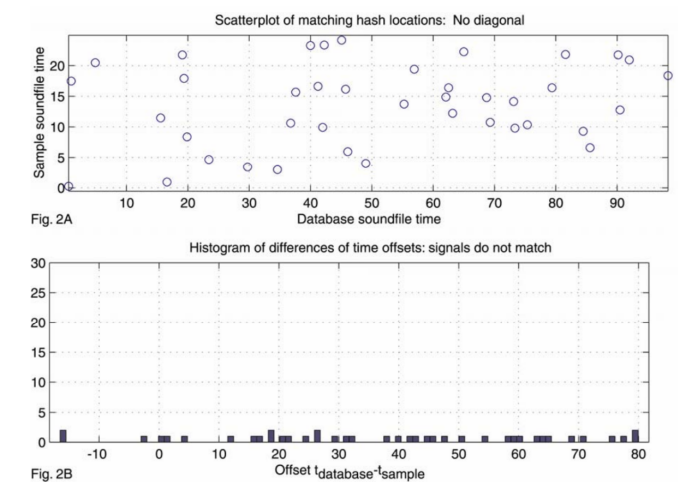
结果判断:
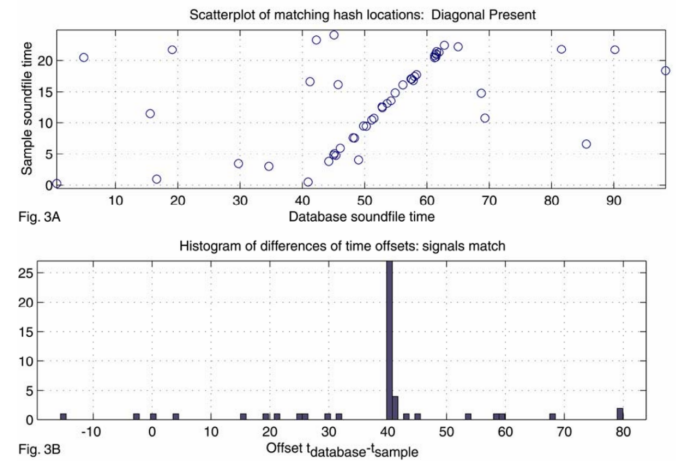
如果目标音乐不在待匹配的音乐列表中,则所匹配的音乐的时间差列表一般来说是一个随机分布的结果,如果有一个正确的匹配结果,则所匹配的音乐的时间差列表中有一个很大的时间差分布结果。可以通过一个合适的阀值,来判断有没有匹配到一个正确的结果。而这个时间差,就是匹配到的音乐的起始位置。
该音乐与目标音频不相关的情况:
该音乐与目标音频匹配的情况:
算法实现
音频指纹提取:
//读入wav文件
memset(&wavData, 0, sizeof(wavData));
readWave(wavFile, &wavData);
//创建音频指纹提取器
recognizer = vr_createVoiceRecognizer2(pt);
vr_setRecognizerListener(recognizer, NULL, voiceMatchFromWave_recognizerPatternListener);
//写入音频数据
vr_writeDataSyn(recognizer, wavData.data, wavData.size);
//获取当前voiceRecognizer的voicePattern
pattern = vr_getVoicePattern(recognizer, -1);
//转成base64
patternBase64 = vr_voicePatternToBase64(pattern);
//保存voicePattern为base64的文件
saveFile(patternBase64FileName, patternBase64, strlen(patternBase64));
vr_destoryVoicePattern(pattern);
音频指纹的识别过程:
//创建音频指纹voiceMatcher
matcher = vr_createVoicePatternMatcher();
//把指定的目标音频指纹voicePattern送入voiceMatcher
for (i = 1; i < argc && i < sizeof(patterns)/sizeof(void *); i ++)
{
pFile = fopen(argv[i], \"rb\");
fileSize = filelength(fileno(pFile));
patternBase64 = (char *)mymalloc(fileSize+1);
fread(patternBase64, 1, fileSize, pFile);
patternBase64[fileSize] = 0;
fclose(pFile);
//base64的voicePattern还原成内存对象
patterns[i] = vr_base64ToVoicePattern(patternBase64);
if (i < argc-1)
{
//音频指纹voicePattern送入voiceMatcher
vr_addVoicePattern(matcher, i, patterns[i]);
}
}
//匹配
vr_matchVoicePattern(matcher, patterns[argc-1], matchStreams, matchResults, sizeof(matchStreams)/sizeof(short), &matched);
//打印各路音频指纹voicePattern的匹配情况
for (i = 0; i < matched; i ++)
{
printf(\"%s:%d\\n\", argv[matchStreams[i]], matchResults[i]);
}
//删除音频指纹voicePattern对象
for (i = 0; i < sizeof(patterns)/sizeof(void *); i ++)
{
if (patterns[i] != NULL)
{
vr_destoryVoicePattern(patterns[i]);
}
}
//删除voiceMatcher
vr_destoryVoicePatternMatcher(matcher);
程序运行
场景准备
程序功能:
savePattern.exe程序的功能是对音频文件产生特征的。
patternMatch.exe程序是在多个音频流中识别是否含有某个目标音频的。
准备的音频文件:
139.wav
BAC009S0724W0136.wav
BAC009S0724W0138.wav
BAC009S0724W0139.wav
BAC009S0724W0144.wav
BAC009S0724W0136.wav,BAC009S0724W0138.wav,BAC009S0724W0139.wav,BAC009S0724W0144.wav是4个不同的音频,139.wav是BAC009S0724W0139.wav的录音文件。模拟的情况是检测在录制的音频中是否含有4个音频的内容。
运行
先产生所有音频的特征文件:
savePattern.exe 139.wav
savePattern.exe BAC009S0724W0136.wav
savePattern.exe BAC009S0724W0138.wav
savePattern.exe BAC009S0724W0139.wav
savePattern.exe BAC009S0724W0144.wav
产生的特征文件如下:
139.wav.base64.txt
BAC009S0724W0136.wav.base64.txt
BAC009S0724W0138.wav.base64.txt
BAC009S0724W0139.wav.base64.txt
BAC009S0724W0144.wav.base64.txt
指纹匹配
运行patternMatch.exe检测目标特征中是否含有指定的音频:
patternMatch.exe BAC009S0724W0136.wav.base64.txt BAC009S0724W0138.wav.base64.txt BAC009S0724W0139.wav.base64.txt BAC009S0724W0144.wav.base64.txt 139.wav.base64.txt
time match count:191, time pair match count:3316
match cost:0
BAC009S0724W0139.wav.base64.txt:72
BAC009S0724W0136.wav.base64.txt:13
BAC009S0724W0138.wav.base64.txt:12
BAC009S0724W0144.wav.base64.txt:5
匹配速度很快,4路音频中去匹配目标音频,花费0毫秒。
画个图看看:
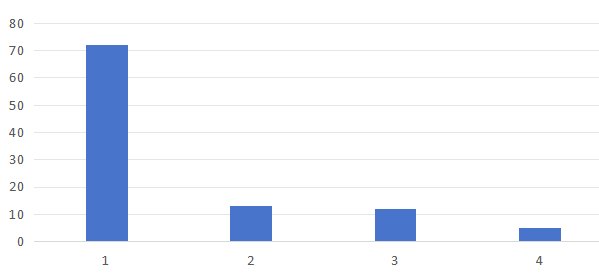
可见BAC009S0724W0139.wav.base64.txt的匹配度明显高于其它音频,所以我们可以认为139.wav.base64.txt与BAC009S0724W0139.wav.base64.txt是匹配的,也就是139.wav含有BAC009S0724W0139.wav音频的内容。
微信版的识别体验在这里:
在播放演示信号视频时打开该页面,模拟的场景是你正在参与某个电台信号互动时跳转到他们的互动页面。

程序下载
其它详情可查看:http://blog.csdn.net/softlgh
作者: 夜行侠 微信号:softlgh, QQ:3116009971, 邮件:3116009971@qq.com
其它声音处理方面程序:
声波通讯:
3分钟为你的应用添加声波通讯功能
android/iphone/windows/linux/微信声波通讯库
Android/iphone/微信手机通过声波初始化智能设备的WIFI信息
哭声识别:
基于设备端的婴儿哭声识别
鼾声识别:
基于设备端的鼾声识别

