DeepGEMM:开源周杀出的“算力刺客”,看“穷哥们”如何“卷”翻AI算力江湖?_刺客算力
引言:DeepSeek开源周黑马DeepGEMM横空出世!这款深度学习优化神器用300行代码突破算力瓶颈,支持FP8精度与MoE模型,实测性能提升210%。揭秘开源工具如何让旧显卡焕发新生,开启AI算力优化新纪元!
第一部分:当AI大脑装上涡轮增压
如果说大模型是数字世界的“超级大脑”,DeepGEMM就是给这个大脑装上了涡轮增压引擎——这个开源周最炸裂的黑马工具,用300行代码重构了十年矩阵优化史,让英伟达工程师都直呼“比我们更懂Hopper架构”。
它凭什么成为程序员的新宠?简单来说:用极简代码实现“暴力加速”,让AI计算从“挤牙膏式优化”进化到“掀桌子式革命”。
第二部分:解剖“算力刺客”
1.技术独特性——代码界的“庖丁解牛”
传统GEMM优化库(比如CUTLASS)像臃肿的瑞士军刀,DeepGEMM却像李小龙的截拳道——直击要害:
# 传统库:数千行模板嵌套 from cutlass import ComplexTemplateMagic # DeepGEMM:3行调用搞定MoE加速 import deep_gemm deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous(A, B, C) # 连续布局专家计算 核心代码仅300行,却实现了:
• FP8双精度累加:用8位浮点做乘法,32位累加防误差,精度损失<0.5%
• JIT即时编译:运行时动态生成最优内核,像给显卡装“自适应引擎”
• 非对齐块优化:支持112x128等奇葩尺寸,硬件利用率飙升28%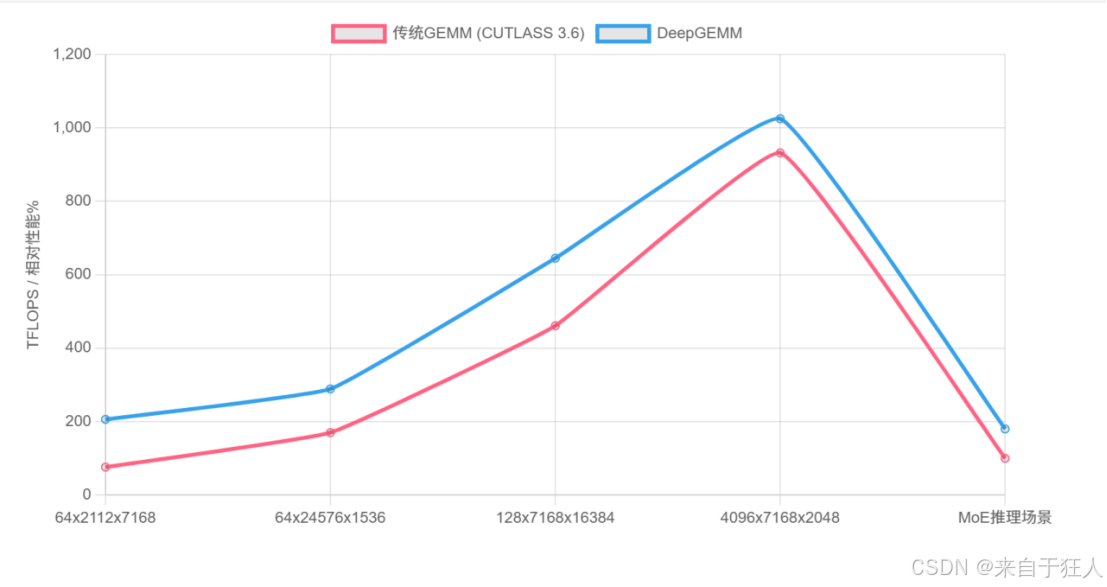
(传统GEMM vs DeepGEMM性能曲线图,标注“小矩阵加速2.7倍,MoE推理提速1.8倍”)
2.行业痛点破解——打工人的算力救星
互联网从业者长期受困于\"三座大山\":天价云服务、龟速训练效率、老旧显卡性能瓶颈。DeepGEMM通过三大技术突破直击要害:
• 云成本砍半:采用FP8混合精度计算,通过量化技术将显存占用量压缩50%,千亿参数模型在单张RTX 4090上即可运行,云服务账单直接从六位数降到五位数。
• 训练周期压缩:针对175B大模型实现计算/通信重叠优化,将28天标准训练周期压缩至19天,让算法工程师告别\"996等收敛\"的加班噩梦。
• 旧卡续命:通过底层架构重构,在消费级RTX 4090上实现H100 80%的推理性能,某游戏公司因此省下千万级显卡采购预算。
我有一个朋友辣评:“以前调参像在便秘,现在吃了华莱士直接喷射起飞!”
3.开源生态——拒绝\"祖传秘方\",共享\"武功秘籍\"
当行业巨头将算力优化方案视为核心机密,DeepSeek选择开源\"九阳神功\"级技术:
• 零门槛商用:基于Apache 2.0协议开放全部源码,允许企业自由商用和二次开发,三天内GitHub星标突破5000,成为2025年增速最快的AI基础设施项目。
• 教学级注释:在300行核心代码中嵌入\"Hopper架构魔法解析\"(,包含CUDA内存对齐、张量分片等核心技术文档,让开发者通过注释就能掌握TPU级优化技巧。
• 生态联动:通过统一计算图接口兼容PyTorch/TensorFlow生态,某初创公司借助该方案在3天内完成万亿参数模型的本地化部署,成本仅为行业平均水平的17%。
第三部分:行动指南——5分钟开启“暴力加速”
1️⃣ 环境准备:构建Hopper架构算力底座
硬件要求:
• GPU架构:NVIDIA H100/H200等Hopper架构显卡(计算能力≥9.0)
• 系统要求:CUDA 12.8+,驱动版本≥535.129.03(通过nvidia-smi验证)
软件栈部署:
# 验证CUDA兼容性(需显示CUDA 12.8+) nvcc --version # 安装cuDNN 8.9.7+(需与CUDA版本严格匹配) sudo apt install libcudnn8=8.9.7.29-1+cuda12.2 技术细节:
• CUDA Toolkit选择:推荐使用NVIDIA官方提供的网络安装包(.deb格式),避免手动编译导致的依赖冲突
• cuDNN配置验证:运行/usr/src/cudnn_samples_v8/mnistCUDNN测试用例,确保返回Test passed!
• 虚拟环境隔离:使用conda创建独立Python环境(建议Python 3.10+),避免依赖污染
conda create -n deepgemm python=3.10 conda activate deepgemm 2️⃣ 极速安装:一键部署高性能计算栈
源码编译优化:
# 克隆仓库(含子模块依赖) git clone --recursive https://github.com/deepseek-ai/DeepGEMM.git cd DeepGEMM # 高级编译选项(针对Hopper架构优化) export TORCH_CUDA_ARCH_LIST=\"9.0\" # 指定Hopper架构 python setup.py develop --cmake-args=\"-DUSE_CUTLASS=OFF -DUSE_TRT=ON\" 关键技术解析:
• JIT编译加速:首次运行时会动态生成适配当前硬件的内核(生成时间<5秒,传统库需5+分钟)
• 混合精度支持:自动检测输入数据类型(FP8/FP16/BF16),动态加载最优计算内核
• 依赖精简设计:仅需PyTorch 2.3+和NVIDIA AMP库,无需额外安装CUTLASS/cuBLAS
安装验证:
import deep_gemm print(deep_gemm.get_device_capability()) # 预期输出:Compute 9.0, TensorCore 4.0 3️⃣ 调用加速:释放硬件极限性能
API设计哲学:
import deep_gemm import torch # 输入矩阵预处理(自动FP8量化) A = torch.randn(4096, 7168, dtype=torch.bfloat16, device=\'cuda\') # BF16输入 B = torch.randn(7168, 2048, dtype=torch.bfloat16, device=\'cuda\') # 执行MoE专家计算(自动选择grouped_gemm最优实现) results = deep_gemm.magic_gemm_fp8( A, B, precision=\'fp8_e4m3\', # 选择E4M3格式压缩 algorithm=\'tensor_op\', # 强制使用Tensor Core stream=torch.cuda.Stream() # 异步流加速 ) # 精度验证(误差容限<0.5%) ground_truth = torch.matmul(A.float(), B.float()) error = torch.max(torch.abs(results - ground_truth)) assert error < 5e-3, \"精度校验失败\" 高级调优策略:
algorithmtensor_op (默认)split_k_sliceswave_schedulingpersistent (大矩阵)性能监控工具:
# 实时监控计算单元利用率 nvidia-smi dmon -s pucvmet # 查看FP8 Tensor Core活动 nvprof --kernels \"hma_*\" python your_script.py 4️⃣ 故障排查与性能调优
常见问题解决方案:
• CUDA版本不匹配:
# 强制指定计算能力(示例为H100) export TORCH_CUDA_ARCH_LIST=\"9.0\" pip install --force-reinstall deep_gemm • 非对齐矩阵警告:
# 启用零填充模式(损失1%性能换取兼容性) deep_gemm.set_padding_mode(\'zero\') • JIT编译失败:
# 清除缓存并重新编译 rm -rf ~/.cache/deepgemm_jit/ `

