C++ onnxruntime库安装与使用 Ubuntu_onnxruntime安装
一、Ubuntu中安装onnxruntime
1、一些依赖
一键安装ROS(不安装ROS可能会缺很多库,容易报错):
wget http://fishros.com/install -O fishros && . fishrosonnxruntime的一些依赖项:
$ sudo apt-get update$ sudo apt-get install -y libprotobuf-dev protobuf-compiler2、onnx安装
$ git clone https://github.com/microsoft/onnxruntime$ cd onnxruntime$ git checkout v1.19.0$ ./build.sh --config Release --build_shared_lib --parallel --allow_running_as_root$ cd onnxruntime/build/Linux/Release/$ sudo make install二、一些报错及解决
1、Protocol Buffer Compiler Permission Denied
NVCC_ERROR = NVCC_OUT = No such file or directory-- CMAKE_CXX_COMPILER_ID: GNU-- CMAKE_CXX_COMPILER_VERSION: 9.4.0-- Using -mavx2 -mfma flags-- Configuring done (2.3s)-- Generating done (0.8s)-- Build files have been written to: /home/codeit/onnxruntime/build/Linux/Release2025-05-28 02:29:05,135 build [INFO] - Building targets for Release configuration2025-05-28 02:29:05,136 build [INFO] - /usr/local/bin/cmake --build /home/codeit/onnxruntime/build/Linux/Release --config Release -- -j6[ 0%] Running C++ protocol buffer compiler on /home/codeit/onnxruntime/build/Linux/Release/_deps/onnx-build/onnx/onnx-ml.proto/bin/sh: 1: /usr/local/bin/protoc-3.21.12.0: Permission deniedmake[2]: *** [_deps/onnx-build/CMakeFiles/gen_onnx_proto.dir/build.make:74: _deps/onnx-build/onnx/onnx-ml.pb.cc] Error 126make[1]: *** [CMakeFiles/Makefile2:7507: _deps/onnx-build/CMakeFiles/gen_onnx_proto.dir/all] Error 2make[1]: *** Waiting for unfinished jobs....[ 0%] Built target absl_strerror[ 1%] Built target absl_spinlock_wait[ 1%] Built target absl_log_severity[ 1%] Built target absl_utf8_for_code_point[ 2%] Built target absl_time_zonemake: *** [Makefile:146: all] Error 2Traceback (most recent call last): File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 2971, in sys.exit(main()) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 2861, in main build_targets(args, cmake_path, build_dir, configs, num_parallel_jobs, args.target) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 1729, in build_targets run_subprocess(cmd_args, env=env) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 860, in run_subprocess return run(*args, cwd=cwd, capture_stdout=capture_stdout, shell=shell, env=my_env) File \"/home/codeit/onnxruntime/tools/python/util/run.py\", line 49, in run completed_process = subprocess.run( File \"/usr/lib/python3.8/subprocess.py\", line 516, in run raise CalledProcessError(retcode, process.args,subprocess.CalledProcessError: Command \'[\'/usr/local/bin/cmake\', \'--build\', \'/home/codeit/onnxruntime/build/Linux/Release\', \'--config\', \'Release\', \'--\', \'-j6\']\' returned non-zero exit status 2./bin/sh: 1: /usr/local/bin/protoc-3.21.12.0: Permission denied 表明 protoc(Protocol Buffer 编译器)没有执行权限,使用以下命令查看 /usr/local/bin/protoc-3.21.12.0 文件的权限:
ls -l /usr/local/bin/protoc-3.21.12.0如果没有执行权限,可以使用以下命令添加执行权限:
sudo chmod +x /usr/local/bin/protoc-3.21.12.02、static assertion failed: Non-compatible flatbuffers version included
In file included from /home/codeit/onnxruntime/onnxruntime/core/framework/kernel_type_str_resolver.cc:8:/home/codeit/onnxruntime/onnxruntime/core/flatbuffers/schema/ort.fbs.h:12:46: error: static assertion failed: Non-compatible flatbuffers version included 12 | FLATBUFFERS_VERSION_MINOR == 5 && | ^[ 22%] Building CXX object CMakeFiles/onnxruntime_framework.dir/home/codeit/onnxruntime/onnxruntime/core/framework/memcpy.cc.oIn file included from /home/codeit/onnxruntime/onnxruntime/core/framework/kernel_type_str_resolver_utils.cc:11:/home/codeit/onnxruntime/onnxruntime/core/flatbuffers/schema/ort.fbs.h:12:46: error: static assertion failed: Non-compatible flatbuffers version included 12 | FLATBUFFERS_VERSION_MINOR == 5 && | ^make[2]: *** [CMakeFiles/onnxruntime_framework.dir/build.make:468: CMakeFiles/onnxruntime_framework.dir/home/codeit/onnxruntime/onnxruntime/core/framework/kernel_type_str_resolver.cc.o] Error 1make[2]: *** Waiting for unfinished jobs....make[2]: *** [CMakeFiles/onnxruntime_framework.dir/build.make:482: CMakeFiles/onnxruntime_framework.dir/home/codeit/onnxruntime/onnxruntime/core/framework/kernel_type_str_resolver_utils.cc.o] Error 1make[1]: *** [CMakeFiles/Makefile2:1950: CMakeFiles/onnxruntime_framework.dir/all] Error 2make: *** [Makefile:146: all] Error 2Traceback (most recent call last): File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 2971, in sys.exit(main()) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 2861, in main build_targets(args, cmake_path, build_dir, configs, num_parallel_jobs, args.target) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 1729, in build_targets run_subprocess(cmd_args, env=env) File \"/home/codeit/onnxruntime/tools/ci_build/build.py\", line 860, in run_subprocess return run(*args, cwd=cwd, capture_stdout=capture_stdout, shell=shell, env=my_env) File \"/home/codeit/onnxruntime/tools/python/util/run.py\", line 49, in run completed_process = subprocess.run( File \"/usr/lib/python3.8/subprocess.py\", line 516, in run raise CalledProcessError(retcode, process.args,subprocess.CalledProcessError: Command \'[\'/usr/local/bin/cmake\', \'--build\', \'/home/codeit/onnxruntime/build/Linux/Release\', \'--config\', \'Release\', \'--\', \'-j6\']\' returned non-zero exit status 2. /home/codeit/onnxruntime/onnxruntime/core/flatbuffers/schema/ort.fbs.h:12:46: error: static assertion failed: Non-compatible flatbuffers version included: FLATBUFFERS_VERSION_MINOR == 5 表明代码期望的 FlatBuffers 版本的次版本号是 5,但实际包含的版本(25.2.10)不满足这个条件( 25.2.10的次版本号为 2)
检查FlatBuffers 版本:
flatc --version安装指定版本的 FlatBuffers:
git clone https://github.com/google/flatbuffers.gitcd flatbuffersgit checkout v23.5.26mkdir buildcd buildcmake ..make -j6sudo make install相关的版本可以参考:
Releases · google/flatbuffers · GitHubFlatBuffers: Memory Efficient Serialization Library - Releases · google/flatbuffers![]() https://github.com/google/flatbuffers/releases
https://github.com/google/flatbuffers/releases
三、onnxruntime推理
C++ onnxruntime API参考:ONNX Runtime: Ort Namespace Reference
1、初始化onnxruntime环境:
创建包含线程池和其他运行设置的Ort::Env 对象
// create an OrtEnvOrt::Env env(ORT_LOGGING_LEVEL_WARNING, \"RL_controller\");Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, \"RL_controller\");Ort::Env::Env(OrtLoggingLevel logging_level = ORT_LOGGING_LEVEL_WARNING, const char * logid = \"RL_controller\" )/*logid The: log identifierlog_severity_level:The log severity level specifies the minimum severity of log messages to show ORT_LOGGING_LEVEL_VERBOSE: Verbose informational messages (least severe) ORT_LOGGING_LEVEL_INFO: Informational messages ORT_LOGGING_LEVEL_WARNING: Warning messages ORT_LOGGING_LEVEL_ERROR: Error messages ORT_LOGGING_LEVEL_FATAL: Fatal error messages (most severe)*/2、设置会话选项:配置优化器级别、线程数和设备(GPU/CPU)使用
// Create a SessionOptions objectOrt::SessionOptions session_options;// Set graph optimization levelsession_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);// Sets the number of threads used to parallelize the execution within nodessession_options.SetIntraOpNumThreads(4);// 设备使用优先级:先GPU再CPUOrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);// Set graph optimization levelsession_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC)/* https://onnxruntime.ai/docs/performance/model-optimizations/graph-optimizations.htmlGraphOptimizationLevel::ORT_DISABLE_ALL: Disables all optimizationsGraphOptimizationLevel::ORT_ENABLE_BASI: Enables basic optimizationsGraphOptimizationLevel::ORT_ENABLE_EXTENDED: Enables basic and extended optimizationsGraphOptimizationLevel::ORT_ENABLE_ALL: Enables all available optimizations including layout optimizations*/// Sets the number of threads used to parallelize the execution within nodessession_options.SetIntraOpNumThreads(int intra_op_num_threads)/*intra_op_num_threads: Number of threads to useA value of 0 will use the default number of threads*/// Append CUDA provider to session options.SessionOptionsAppendExecutionProvider_CUDA(OrtSessionOptions * options, const OrtCUDAProviderOptions * cuda_options )3、加载模型:加载预训练的ONNX模型,创建Ort::Session对象
std::string policy_path = \"/policies/\" + policy_name + \".onnx\";Ort::Session onnx_session(env, policy_path.c_str(), session_options);// Create a Session objectOrt::Session::Session(const Env & env,const char * model_path,const SessionOptions & options )4、获取模型输入输出信息:数量、名称、类型和形状
std::vector input_node_names;std::vector output_node_names;Ort::AllocatorWithDefaultOptions allocator;// Get the number of model inputsint input_nodes_num = onnx_session.GetInputCount();for (int i = 0; i < input_nodes_num; ++i) {auto input_name = onnx_session.GetInputNameAllocated(i, allocator);input_node_names.push_back(input_name.get()); auto inputShapeInfo = onnx_session.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();int ch = inputShapeInfo[1];input_h = inputShapeInfo[2];input_w = inputShapeInfo[3];}int output_nodes_num = onnx_session.GetOutputCount();for (int i = 0; i < output_nodes_num; ++i) { auto output_name = onnx_session.GetOutputNameAllocated(i, allocator); output_node_names.push_back(output_name.get()); auto outShapeInfo = onnx_session.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();num = outShapeInfo[0];nc = outShapeInfo[1];}// Get input name at the specified indexGetInputNameAllocated(size_t index,OrtAllocator * allocator )// Get input type informationGetInputTypeInfo(size_t index)// Get type information for data contained in a tensor, returns TensorTypeAndShapeInfoGetTensorTypeAndShapeInfo()GetShape()5、推理准备
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);std::array input_shape{1, static_cast(obs_np.size())};Ort::Value input_tensor_ = Ort::Value::CreateTensor(memory_info, obs_np.data(), obs_np.size(), input_shape.data(), input_shape.size());std::vector output_tensor;std::array input_name = {input_node_names[0].c_str()};std::array out_name = {output_node_names[0].c_str()};static MemoryInfo Ort::MemoryInfo::CreateCpu(OrtAllocatorType type, OrtMemType mem_type1 )/* OrtAllocatorType type: OrtInvalidAllocator OrtDeviceAllocator OrtArenaAllocator OrtMemType mem_type1: Memory types for allocated memory, execution provider specific types should be extended in each provider. OrtMemTypeCPUInput: Any CPU memory used by non-CPU execution provider. OrtMemTypeCPUOutput: CPU accessible memory outputted by non-CPU execution provider, i.e. CUDA_PINNED. OrtMemTypeCPU: Temporary CPU accessible memory allocated by non-CPU execution provider, i.e. CUDA_PINNED. OrtMemTypeDefault: The default allocator for execution provider.*/static Value Ort::Value::CreateTensor(const OrtMemoryInfo * info, T * p_data, size_t p_data_element_count, const int64_t * shape, size_t shape_len )/* https://onnxruntime.ai/docs/api/c/struct_ort_1_1_value.html#ab19ff01babfb77660ed022c4057046ef info: Memory description of where the p_data buffer resides (CPU vs GPU etc). p_data: Pointer to the data buffer. p_data_element_count: The number of elements in the data buffer. shape: Pointer to the tensor shape dimensions. shape_len: The number of tensor shape dimensions.*/6、 执行推理
output_tensor = onnx_session.Run(Ort::RunOptions{nullptr}, input_name.data(), &input_tensor, 1, output_name.data(), output_name.size());float* float_array = output_tensor[0].GetTensorMutableData();# Run the model returning results in an Ort allocated vector.std::vector Ort::detail::SessionImpl::Run(const RunOptions & run_options, const char *const * input_names, const Value * input_values, size_t input_count, const char *const * output_names, size_t output_count )/* https://onnxruntime.ai/docs/api/c/struct_ort_1_1detail_1_1_session_impl.html#af5c930bdd9aadf1c9ed154d59fe63a66 run_options input_names: Array of null terminated strings of length input_count that is the list of input names input_values: Array of Value objects of length input_count that is the list of input values input_count: Number of inputs (the size of the input_names & input_values arrays) output_names: Array of C style strings of length output_count that is the list of output names output_count: Number of outputs (the size of the output_names array) returns: A std::vector of Value objects that directly maps to the output_names array (eg. output_name[0] is the first entry of the returned vector)*/R * Ort::detail::ValueImpl::GetTensorMutableData()四、onnxruntime推理代码
1、单.cpp文件
#include #include int main() { // create an OrtEnv Ort::Env env(ORT_LOGGING_LEVEL_WARNING, \"RL_controller\"); Ort::SessionOptions session_options; std::string policy_path = \"/home/zc/4th_humanoid_hust_0429_rt/src/humanoid_rl_control/rl_master/policies/policy_1.onnx\"; Ort::Session onnx_session(env, policy_path.c_str(), session_options); std::vector input_node_names; std::vector output_node_names; Ort::AllocatorWithDefaultOptions allocator; // Get the number of model inputs int input_nodes_num = onnx_session.GetInputCount(); std::cout << \"Number of input nodes: \" << input_nodes_num << std::endl; for (int i = 0; i < input_nodes_num; ++i) { auto input_name = onnx_session.GetInputNameAllocated(i, allocator); std::cout << \"Input node \" << i << \": \" << input_name.get() << std::endl; input_node_names.push_back(input_name.get()); auto inputShapeInfo = onnx_session.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape(); std::cout << \"Input shape: \" << inputShapeInfo.size() << \" dimensions\" << std::endl; std::cout << \"inputShapeInfo[0]: \" << inputShapeInfo[0] << std::endl; std::cout << \"inputShapeInfo[1]: \" << inputShapeInfo[1] << std::endl; } int output_nodes_num = onnx_session.GetOutputCount(); std::cout << \"Number of output nodes: \" << output_nodes_num << std::endl; for (int i = 0; i < output_nodes_num; ++i) { auto output_name = onnx_session.GetOutputNameAllocated(i, allocator); std::cout << \"Output node \" << i << \": \" << output_name.get() << std::endl; output_node_names.push_back(output_name.get()); auto outShapeInfo = onnx_session.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape(); std::cout << \"Output shape: \" << outShapeInfo.size() << \" dimensions\" << std::endl; std::cout << \"outShapeInfo[0]: \" << outShapeInfo[0] << std::endl; std::cout << \"outShapeInfo[1]: \" << outShapeInfo[1] << std::endl; } std::vector obs_np(705, 0); auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); std::array input_shape{1, static_cast(obs_np.size())}; Ort::Value input_tensor = Ort::Value::CreateTensor(memory_info, obs_np.data(), obs_np.size(), input_shape.data(), input_shape.size()); std::vector output_tensor; std::array input_name = {input_node_names[0].c_str()}; std::array output_name = {output_node_names[0].c_str()}; output_tensor = onnx_session.Run(Ort::RunOptions{nullptr}, input_name.data(), &input_tensor, 1, output_name.data(), output_name.size()); std::vector action(12, 0); float* float_array = output_tensor[0].GetTensorMutableData(); for (size_t i = 0; i < 12; ++i) { action[i] = static_cast(float_array[i]); std::cout << action[i] << std::endl; } session_options.release(); onnx_session.release();}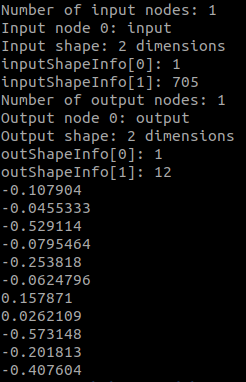
2、.h头文件和.cpp文件
-
onnx_h.h
# onnx_h.h#ifndef ONNX_H_H#define ONNX_H_H#include #include class ONNX {public: void onnx_Init(); std::vector run_onnx(); std::vector obs; private: int input_nodes_num; int output_nodes_num; std::vector input_node_names; std::vector output_node_names; std::array input_name; std::array output_name; Ort::Session *onnx_session = nullptr; std::string policy_path; std::vector action; };#endif // ONNX_H_H-
onnx_cpp.cpp
# onnx_cpp.cpp# include \"onnx_h.h\"void ONNX::onnx_Init() { policy_path = \"/home/zc/4th_humanoid_hust_0429_rt/src/humanoid_rl_control/rl_master/policies/policy_1.onnx\"; // create the ONNX Runtime environment object env and set the logging level to WARNING Ort::Env env(ORT_LOGGING_LEVEL_WARNING, \"ONNX\"); // create the ONNX Runtime session options object: session_options Ort::SessionOptions session_options; // create a default configured allocator instance that allocates and frees memory Ort::AllocatorWithDefaultOptions allocator; onnx_session = new Ort::Session(env, policy_path.c_str(), session_options); // get model input information input_nodes_num = onnx_session->GetInputCount(); std::cout << \"Number of input nodes: \" << input_nodes_num << std::endl; for (int i = 0; i GetInputNameAllocated(i, allocator); std::cout << \"Input node \" << i << \": \" << input_name.get() <GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape(); std::cout << \"Input shape: \" << inputShapeInfo.size() << \" dimensions\" << std::endl; std::cout << \"inputShapeInfo[0]: \" << inputShapeInfo[0] << std::endl; std::cout << \"inputShapeInfo[1]: \" << inputShapeInfo[1] <GetOutputCount(); std::cout << \"Number of output nodes: \" << output_nodes_num << std::endl; for (int i = 0; i GetOutputNameAllocated(i, allocator); std::cout << \"Output node \" << i << \": \" << output_name.get() <GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape(); std::cout << \"Output shape: \" << outShapeInfo.size() << \" dimensions\" << std::endl; std::cout << \"outShapeInfo[0]: \" << outShapeInfo[0] << std::endl; std::cout << \"outShapeInfo[1]: \" << outShapeInfo[1] << std::endl; } // get the name of the first input and output node input_name = {input_node_names[0].c_str()}; output_name = {output_node_names[0].c_str()}; action = std::vector(12, 0.0); obs = std::vector(705, 0.0f);}std::vector ONNX::run_onnx() { // Create input tensor object from obs values auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); std::array input_shape{1, static_cast(obs.size())}; Ort::Value input_tensor = Ort::Value::CreateTensor(memory_info, obs.data(), obs.size(), input_shape.data(), input_shape.size()); std::vector output_tensor; // output tensor // Run the ONNX model output_tensor = onnx_session->Run(Ort::RunOptions{nullptr}, input_name.data(), &input_tensor, 1, output_name.data(), output_name.size()); // Extract the output tensor data float* float_array = output_tensor[0].GetTensorMutableData(); for (size_t i = 0; i < action.size(); ++i) { action[i] = static_cast(float_array[i]); } return action;}int main() { ONNX onnx; onnx.onnx_Init(); // Simulate some observation data std::vector obs(705, 0.0f); for (size_t i = 0; i < obs.size(); ++i) { obs[i] = static_cast(i) / obs.size(); } onnx.obs = obs; // Run the ONNX model std::vector action = onnx.run_onnx(); // Print the action for (const auto& a : action) { std::cout << a << std::endl; } return 0;}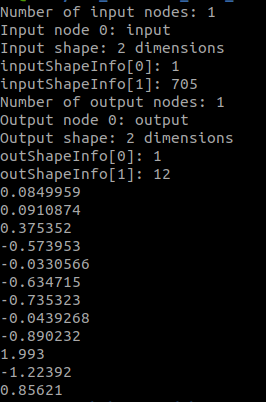
五、参考
【深度学习】【OnnxRuntime】【C++】模型转化、环境搭建以及模型部署的详细教程-CSDN博客
C++环境下onnxruntime推理自定义模型_onnxruntime c++-CSDN博客


