探秘TaoAvatar:淘宝3D真人数字人技术解析

在2025上海AWE焕新消费节的家享生活展馆中,3D数字导购「小淘」以近乎真人的形态与观众自然互动,生动诠释了淘天Meta技术团队最新技术——TaoAvatar的革新力量。这项融合3D高斯重建、AI语音驱动与端侧大模型的尖端技术,突破传统数字人局限,实现从“二次元偶像”到“3D真人复刻”的跃迁。通过高精度建模、多模态交互及工业级量产方案,TaoAvatar不仅以2K级拟真视觉、90FPS流畅动效和自然语音同步技术重塑虚拟交互体验,更将制作成本压缩至传统CG的1/30,周期缩短至一周内。从家电导购到XR沉浸场景,TaoAvatar正以“真实感、智能性、普惠性”三大突破,开启数字人规模化落地的新纪元。
欢迎关注 MNN GitHub:MNN 端侧3D数字人AI对话项目https://github.com/alibaba/MNN/tree/master/apps/Android/Mnn3dAvatar


引言
2025上海AWE焕新消费节,在熙熙攘攘的家享生活展馆里,3D数字导购「小淘」正以自然流畅的语气,结合精准而专业的讲解,向观众介绍最新的家电产品。她逼真立体的形象仿佛真人站在你面前,能敏锐捕捉用户的眼神和关注点,互动自然灵动宛如面对面的真人交流。这背后,正是淘天Meta技术团队最新的 TaoAvatar技术体系 在支撑。


数字人进化论:从二次元偶像到真人复刻
你是否想过,未来的数字世界里,陪你聊天、推荐商品的“人”,将不再是冷冰冰的机器,而是一个拥有真实面孔、细腻表情和丰富情感的“真人”?从初音未来到A-Soul,数字人已经陪伴我们走过了“二次元”时代。而如今,一项名为“3D真人数字人”的黑科技,正突破次元壁,将现实中的物理真人“复刻”到数字世界,彻底重塑我们的虚拟互动体验。
▐ 什么是3D真人数字人?
简单来说,它就像是为你在数字世界中创造了一个1:1的“复制品”。通过多目拍摄、3D重建和AI驱动等先进技术,3D真人数字人能够将现实中的人以令人惊叹的细节和自然度呈现在屏幕上。
你可能好奇,这和我们以往见过的3D虚拟形象有什么不同?答案是:更真实、更智能、更高效!
-
更真实,更亲切
与完全由计算机生成的虚拟形象相比,3D真人数字人拥有更加细腻的面部特征和自然流畅的肢体动
作,仿佛真人就站在你面前,眼神和表情灵动自然,亲和力十足。
-
更智能,更互动
利用AI对话技术,3D真人数字人不仅能精准捕捉并理解用户的情绪,还能根据互动的内容,实时调整语气、表情和动作,带来前所未有的沉浸式体验。
-
更高效,成本更低
过去,制作一个高质量的3D虚拟人通常需要数月的精细打磨和高昂的成本。而借助3D真人数字人的技术,能在保持高拟真度的同时,大幅降低制作成本,表情和动作也能在AI的驱动下更加自然流畅。
TaoAvatar,正是集成了这些前沿技术的3D真人数字人产品。它融合了3D高斯重建(3D Gaussian Splatting)、语音口唇驱动(Talking Head Synthesis)和端侧大语言模型推理引擎(MNN-LLM)等尖端技术,能够为电商导购、虚拟陪伴等场景提供高度拟真的数字人形象,还能在XR设备(如Apple Vision Pro)上带来更加沉浸的互动体验。
效果如何?眼见为实!
TaoAvatar家电导购场景
TaoAvatar手套导购场景

技术破壁:三大维度重构产业标准
▐ 1. 效果维度:从“2D纸片人”到“3D真人”,突破次元壁的视觉效果
相比2D数字人(如某些直播平台的固定半身像),TaoAvatar在三个维度上实现了突破:
-
清晰真实感
TaoAvatar的渲染分辨率突破2D数字人极限的1080P,达到2K级别,全身建模精度PSNR≥35,面部精度超40,细节刻画精细入微,皮肤纹理(如唇纹)、眼睫毛、发丝动态自然,呈现更逼真的视觉效果。同时,TaoAvatar支持动态重建服饰褶皱的物理级还原,服装材质的光泽和动态感真实可感,整体表现更细腻,更具真实感。
-
3D立体感
传统视频数字人受限于单目摄像机位,仿佛“困在莫比乌斯环中的二维生物”。而TaoAvatar突破这一局限,支持任意视角的镜头语言——从特写到全景,从环绕到主观视角,空间表现力堪比电影级调度。在Apple Vision Pro中,用户通过双目视角能直观感受到人物的立体感和空间层次感。90FPS的双目渲染确保无延迟、不卡顿,带来顺滑而沉浸的视觉体验。
-
光影融合感
TaoAvatar支持动态光影重建,自研渲染引擎可实时解算全局光照,使人物光照与背景环境自然融合,地面支持动态阴影,呈现出高度逼真的光场效果,让肉眼几乎难以分辨虚实边界。
▐ 2. 交互维度:从“好看的皮囊”到“有趣的灵魂”,多模态交互的智能升级
好看的皮囊千篇一律,有趣的灵魂百里挑一。TaoAvatar仅靠精致的外观还远远不够,真正让其“活起来”的,是智能的语音问答和自然流畅的表情与动作,否则再精致的形象也只是一个“静态空壳”。
在智能交互上,TaoAvatar结合当前最前沿的大模型技术,依托阿里集团的通义千问开源模型和MNN开源推理引擎,在端侧部署了轻量化的ASR-LLM-TTS语音问答链路。TaoAvatar在Apple Vision Pro上的对话延迟稳定在1~2秒,基于导购领域专业知识微调的Qwen2.5-1.5B模型,设备端内存占用仅为1.2GB,在轻量化的同时保持了高效响应。
在语音驱动上,TaoAvatar自研了Audio2BS语音驱动算法,能够自然表达中英文,音画同步精度LSE-C达到7.0,嘴型驱动的FID保持在5.0以下,精准保留人物的自然嘴型特征,避免了AIGC技术常见的“违和感”。此外,借鉴游戏中的Idle-Talk状态机策略,TaoAvatar在导购场景中实现了语音、表情和动作的自然切换,保证每一句回答都能与表情、动作精准同步,互动自然流畅,真正做到语音、表情、动作的多模态融合。
▐ 3. 成本维度:从“匠人刻刀”到“算法工厂”,工业级量产的革新突破
你可能难以想象,制作一个高质量的超写实CG数字人,涉及雕刻(Sculpting)、拓扑(Retopology)、UV展开(UV Mapping)、贴图(Texturing)和材质调整(Material Editing)等繁琐流程,依赖大量手工精细操作,通常需要耗费数月时间和数十万元成本。即便完成建模,驱动这样的形象仍需专业动捕设备和复杂的后期处理。
然而,AI正在重塑这一切!人工智能正逐步渗透传统CG制作流程,甚至有望实现从建模到动作表情驱动再到智能对话的全链路自动化。TaoAvatar自研的低成本多视角相机阵列,仅需15分钟即可完成真人数字分身的高精度拍摄,表情、手势和动作的捕捉,自研AI动态重建算法在1周内便可交付自然驱动的3D真人数字人,显著降低成本与周期,让超写实数字人真正触手可及。
指标
传统CG制作
TaoAvatar
制作周期
3-5个月
1周
单次成本
30-60万
1-2万
驱动方式
动捕设备
AI语音动作驱动

技术内核:五大核心模块解析
▐ 1. 多目视觉绑定系统:精准捕捉细节
基于多视角三维重建技术,我们构建了一套低成本、高精度的动态拍摄系统。在多视角数据的预处理环节,采用混合标定算法实现RGB相机的空间位姿对齐,结合改进的人像分割与Matting算法,输出时序一致的多视角人像序列。针对少视角重建的挑战,我们创新提出多监督融合优化框架:从2D图像中提取关节点热图、法向流场、轮廓约束等12种弱监督信号,联合驱动SMPLX模型的全局位姿、肌肉形变、微表情及手势参数的精准拟合。
整体方案采用三阶段渐进式优化:
-
部件级解耦绑定:头部绑定采用Flame系数迁移算法,精准捕捉表情BS系数,手部绑定通过图卷积网络解析28个手指关节的姿态,身体绑定结合逆运动学(IK)与物理碰撞约束,确保姿态自然协调。
-
跨模态融合:将Photometric误差、时序光流一致性、解剖学先验等约束融入联合优化目标函数,解决少视角下的姿态抖动问题。
-
高模重建增强:通过给SMPLX添加衣服和头发等非裸体几何以及自动蒙皮,我们扩展SMPLX到SMPLX++;然后基于神经网络学习nonrigid形变场,为SMPLX++构建pose-correctives来表达姿态相关的dynamics。最终输出几何完整、拓扑一致、包含服饰褶皱等动态细节的人物几何序列。

TaoAvatar 3D人体模版模型SMPLX++制作流程
该方案在30万元级设备投入下,实现单次拍摄、周级交付的工业级生产稳定性,兼顾高精度与高效率。完整的数据方案和建模结果已在我们开源的数据集TalkBody4D中发布,欢迎访问和参考。
TalkBody4D: a multi-view dataset designed for full-body talking scenarios, featuring diverse facial expressions and gestures with synchronous audios.(链接见下文附录)
▐ 2. 动态高斯重建黑科技:实时高保真建模
3D数字人建模的主流表示方式包括显式表示和隐式表示。显式表示(如点云、多边形网格)在游戏和影视制作中广泛应用,具备直接可编辑性,但在复杂几何和动态场景下计算成本高。隐式表示(如SDF、NeRF、3D Gaussian Splatting)借助神经网络逼近隐式函数,能够恢复精细的几何与纹理。其中,2023年SIGGRAPH最佳论文3D Gaussian Splatting(3DGS)作为一种基于光栅化的表示方法,兼具实时渲染与高效表示能力,正成为数字人建模的研究热点。
尽管3DGS在实时渲染和静态重建中展现出巨大潜力,但在动态人体建模中仍面临动态渲染闪烁、数据量庞大和端侧性能瓶颈三大挑战。为攻克这些难题,TaoAvatar提出了一套突破性的3DGS人体动态重建方案:
-
动态渲染优化:引入Mesh Tracking渐进式优化策略,结合时序法向流场约束与跨帧光度一致性损失,使PSNR接近静态重建的精度,有效消除动态渲染中的闪烁。
-
数据存储优化:通过联合动态重建框架,将15秒序列的存储量从6GB压缩至160MB,训练时长从100小时缩短至10小时,实现每帧25万高斯点云在统一拓扑下的参数共享,显著提升重建效率。
-
端侧实时推理:针对端侧大网络的性能瓶颈,采用Teacher-Student知识蒸馏策略,使小模型在保持高保真效果的同时,确保端侧设备上的高效实时运行。
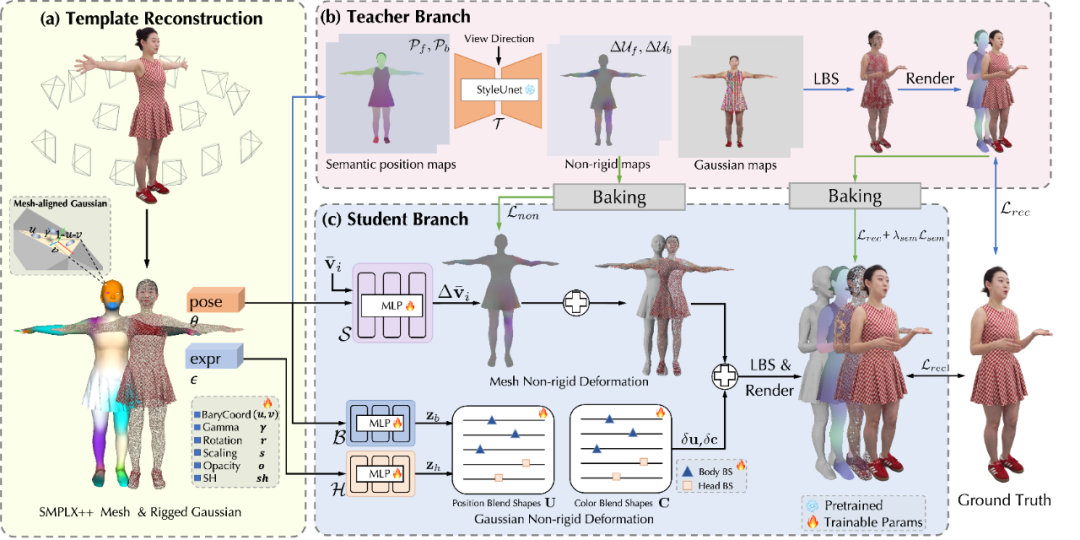
TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting, CVPR 2025
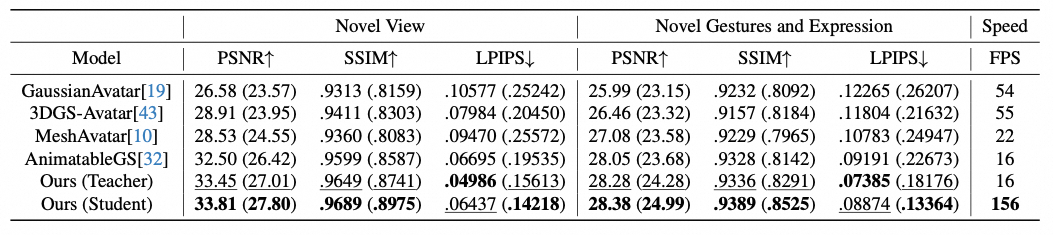
TaoAvatar核心指标与SOTA方案的对比
这一方案显著提升了动态重建和渲染的效率与表现力,并在多个应用场景中展现出卓越性能。更多技术细节,详见我们CVPR 2025 Highlight论文:TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting(https://arxiv.org/abs/2503.17032)
▐ 3. 语音驱动创新方案:自然口型与表情联动
为了让3D真人数字人“开口说话”,我们研发了GaussianTalker算法,突破了实时语音驱动的同步性、逼真度和一致性难题。现有2D语音口唇驱动算法普遍存在三方面局限:嘴型与发音的精确同步(需精准呈现闭唇、噘嘴等复杂口型)、身份特征稳定性(需保证逐帧生成的人物形象一致性)以及三维动态自然度(需适应不同头部姿态和细微表情的变化)。
我们提出的GaussianTalker方案创新性地融合3D Gaussian Splatting的显式表征优势,通过将高斯点云与Flame人脸模型动态绑定,实现人脸运动的直观有效控制。核心技术架构包含:
-
个性化表情生成模块:采用跨音色音频编码器提取语音内容特征,结合说话人身份编码进行特征增强,精准预测个性化唇形与表情参数。
-
动态高斯渲染模块:基于FLAME网格动态驱动高斯点云,通过可学习BlendShapes生成面部细节,结合Inpainting Generator消除运动伪影,确保高效、逼真的渲染质量。
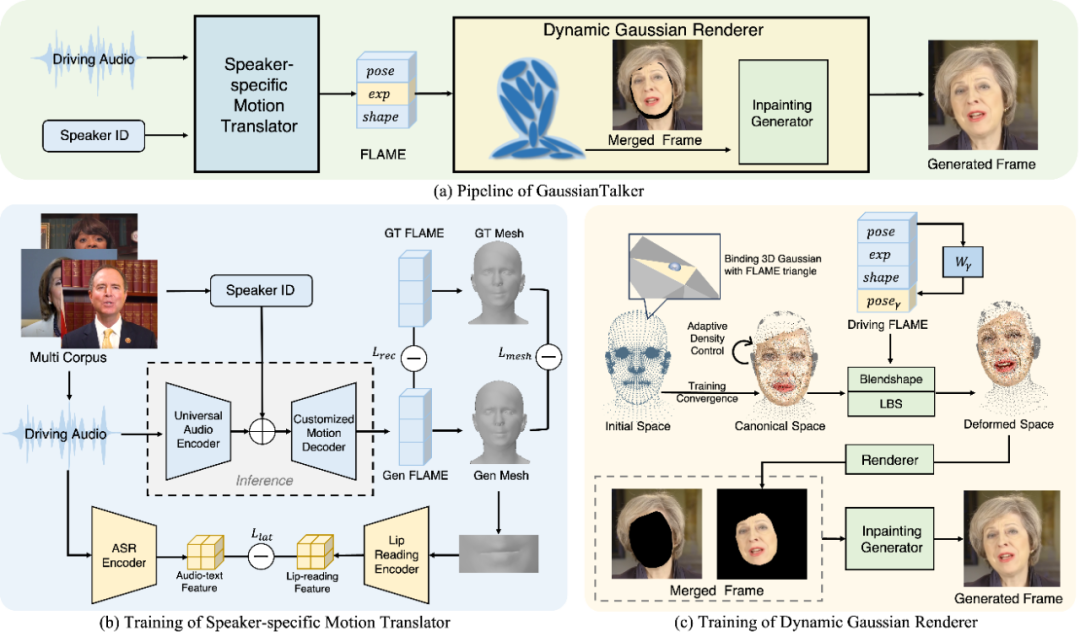
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting, ACM-MM 2024
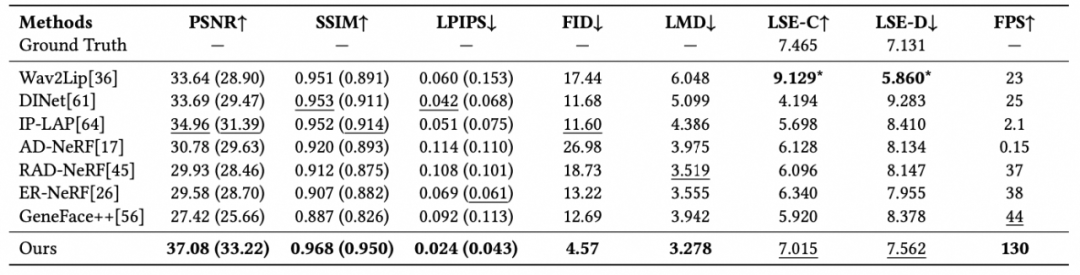
GaussianTalker核心指标和SOTA方案的对比
实验结果表明,GaussianTalker在说话人脸合成的唇形同步性、说话自然度和渲染视觉质量等指标上全面超越当前SOTA方法,且在消费级GPU上实现了130FPS的实时渲染,具备在CPU等端侧设备上的部署潜力。更详细的技术细节可以参阅我们ACM-MM 2024的论文:GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting(https://dl.acm.org/doi/10.1145/3664647.3681675)
▐ 4. 端侧高效渲染引擎:稳定流畅细节呈现
-
丰富的高斯渲染特性
AceNNR引擎不仅支持渲染静态及动态高斯模型,还支持将高斯渲染和引擎已有的各种渲染特性相结合,很大程度上丰富了高斯渲染的表现力。主要包括:
-
几何&高斯混合渲染:支持同时渲染几何模型与高斯模型,保证正确的相互遮挡关系及颜色混合效果。
-
高斯模型重光照:支持使用自定义光照或AR提供的实时环境光照亮高斯数字人,使其更好融入环境,渲染效果可随着真实环境光照实时变化。
-
高斯粒子特效:支持将高斯点作为粒子进行仿真,实现丰富的高斯模型粒子效果,同时也支持和VFX系统联动,实现复杂的动效。
几何&高斯混合渲染:将高斯数字人
放在几何模型组成的CG场景中

高斯模型重光照:高斯数字人光照效
果随环境光照变化

高斯粒子特效:以高斯点为粒子进行
仿真渲染
高斯模型VFX溶解效果:高斯渲染受
VFX效果控制
-
极致的性能优化
为了在VR及移动端设备上做到实时渲染高斯模型,我们做了大量性能优化,其中涉及渲染管线定制、数据压缩、渲染剔除、排序加速、基础渲染算法优化及双目渲染优化等,最终我们取得了业界领先的高斯模型实时渲染性能,在Apple Vision Pro上以2K分辨率实时渲染动态高斯模型帧率达到90FPS。主要性能优化包括:
-
GPU-Driven高斯渲染管线:我们实现了一条高性能的GPU-Driven高斯渲染管线以保证能在VR及移动端设备上实时渲染高斯模型,所有pass均在GPU侧执行,整个渲染流程几乎没有GPU和CPU的通信开销。通过合理的GPU线程编排每个pass内的计算都做到高度并行,充分利用了GPU的算力加速整个渲染流程。
-
Splat数据压缩:我们实现了一种高效的splat数据压缩算法,该算法支持在GPU侧并行解压以及按需解压的能力。另外,通过逐属性独立压缩在保证渲染质量的同时增加了高斯模型的整体压缩率。
-
多级渲染剔除:高斯实时渲染前会先做剔除以保证只有可见splat被渲染,我们依次从模型、面、splat三级粒度对渲染数据做剔除,最终实际渲染的splat数量远少于总数。
-
Splat排序加速:我们实现了一种高效的GPU排序算法,通过合理的GPU线程编排以及充分利用现代化GPU加速指令提高了排序速度。另外,排序基于剔除结果进行,仅可见的splat会参与排序。
-
Splat高效渲染:我们将splat作为mesh渲染,这使得高斯渲染可以充分利用VR及移动端设备自带的硬件渲染管线能力。另外,我们通过优化mesh结构及仅提交可见splat进一步优化了渲染性能。
-
LOD:我们实现了高斯模型的LOD能力,渲染时splat的属性会随投影面积动态调整,在增强高斯渲染质量的同时也提高了渲染性能。
-
双目高斯渲染:Apple Vision Pro上需使用双目渲染,这给实时渲染性能带来巨大的挑战。为优化双目渲染性能,在整个渲染流程中我们尽可能在双目间复用计算结果。我们将视角无关及视角相关的计算拆分到不同pass,前者可直接被双目共享,后者通过合理地近似计算也做到双目共享部分计算结果,最终达到高帧率实时渲染的能力。
▐ 5. 端侧智能推理引擎:本地算力实时响应
端侧部署大语言模型面临算力不足、内存受限、推理延迟、功耗过高和精度损失等多重挑战。MNN-LLM 是一款高效的端侧大模型推理框架,支持大语言模型(LLM)在移动设备(如 8Gen1)上运行。它通过动态量化、预推理、磁盘映射和 KV 缓存管理等技术创新,显著提升了推理效率和内存利用率,突破了移动端部署的性能瓶颈。
核心技术亮点:
-
端侧部署与兼容性: 支持使用CPU(Arm或x86架构)、GPU(Metal或OpenCL)进行推理,支持各类移动设备部署。
-
动态量化:支持 int4/int8 的 block wise /channel wise 量化,支持混合精度量化(模型中各算子按重要程度采用不同的量化方案)以降低模型体积大小和内存占用(混合精度量化后Qwen2.5-1.5B的模型体积和内存占用由 5.58 G 下降到 1.2 G)。在 CPU 上利用量化计算指令(sdot/smmla 指令),结合对输入动态量化实现推理加速。在 GPU 上,在 Kernel 内部反量化,结合新特性(OpenCL 的 recordable queue 和 Metal 的 simdgroup)加速推理。在 8Gen3 上,Qwen2.5-1.5B 模型解码速度最高 45 token/s。
-
预推理:在模型加载且输入形状确定后,对模型权重进行重排,对计算方案进行寻优(试跑或经验公式计算),牺牲一定的启动时间以使不同设备上的CPU和GPU都达到最优的模型预填充和解码性能。
-
KV 缓存与量化:内置KV Manager 模块,以支持 KV 缓存的扩容、量化与预加载,减少长序列生成时的内存压力。
-
磁盘映射:支持 KV缓存和模型权重映射到磁盘(基于mmap实现),以避免内存溢出,确保长时间稳定运行。
-
LoRA 多任务加载: 基于 MNN 权重共享,支持同时加载多个 LoRA,单个 LoRA 仅增加少量内存(性能损失在 10% 以内)。
-
完整推理链路: 提供从模型导出、量化到推理的全流程工具链,兼容 PyTorch/TensorFlow 训练模型,直接转换为 MNN 格式,简化部署流程。
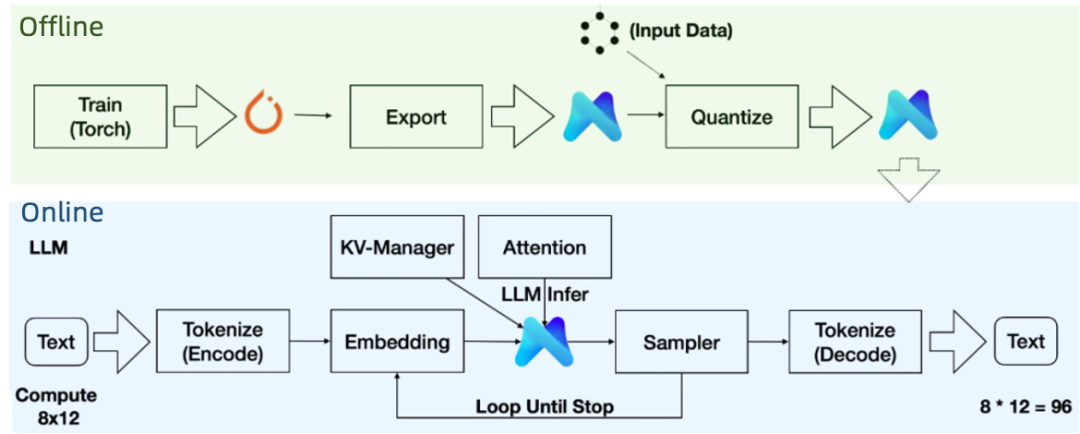
MNN-LLM核心框架
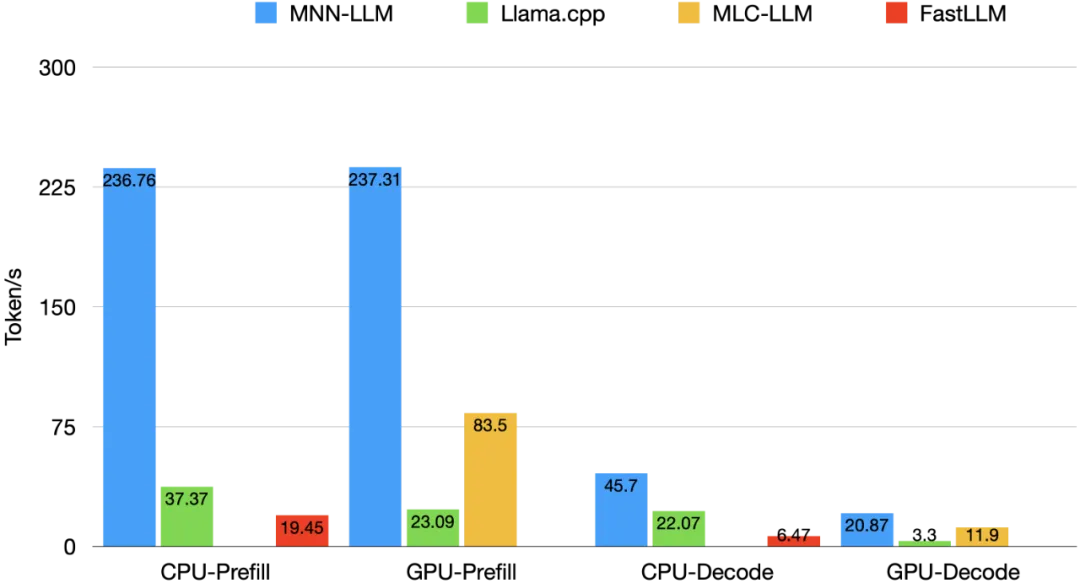
MNN核心指标和SOTA框架的对比
未来,MNN 将持续提升推理效率,探索更低精度计算和更广泛的模型兼容性,进一步推动端侧 AI 技术的发展。MNN-LLM 已开源,我们也将在近期开源手机端实时 AI 对话的 3D 真人数字人,欢迎关注MNN GitHub:
MNN 端侧3D数字人AI对话项目:https://github.com/alibaba/MNN/tree/master/apps/Android/Mnn3dAvatar
MNN 端侧LLM大模型推理引擎:https://github.com/alibaba/MNN/tree/master

商业验证:两大场景实战数据
▐ 1.淘宝Vision - AWE天猫虚拟家居体验舱:小试牛刀,精彩初现
在本次 AWE 展会上,淘宝 Vision 联合天猫家享生活行业打造的虚拟家居体验舱惊艳亮相,吸引众多用户排队打卡,沉浸式体验,飞上万米高空、睡在云朵床上、穿越星际空间、畅玩互动游戏,最终降落在外星球的温暖太空舱中,感受世外桃源般的舒适生活。
“太神奇了!”“从来没有过的体验,太美妙了!”“就像一个沉浸式的剧场!”——用户纷纷感叹。当他们在空间中点击“小淘讲解”时,TaoAvatar便以逼真的 3D 形象出现在面前,详细讲解虚拟家居中的云朵床、电竞椅、卡萨帝星悦系列家电等商品,解锁更多产品功能与细节。
淘宝 Vision 团队还在展区内创新性地引入第三视角现场直播。除戴上 Vision Pro 的体验者外,路过的观众也能通过现场大屏,实时观看当前体验者的视角及与TaoAvatar数字人“小淘”的互动。更精彩的是,这一画面同步在淘宝直播中实时呈现,让更多线上用户参与其中。
对品牌商家而言,淘宝 Vision 将 3D人工智能导购与沉浸式购物场景相结合,不仅创新了购物体验,还有效降低人力成本,提供了一种线上线下结合的全新解决方案,打造更具科技感和未来感的购物方式。
▐ 2. 淘宝Vision - 未来旗舰店:商业级部署,诚邀体验
早在去年,淘宝 Vision App 发布,就成为首个集成“商详”、“搜索”、“交易”、“订单”等完整功能的XR电商 APP,荣获2025年度Apple设计大奖-“出色互动”类大奖、中国区 Vision Pro 首发应用、Vision Pro Store 推荐应用等多项荣誉,并成为苹果门店预装应用,目前也是Apple Vision Pro 上唯一具备完整功能的电商 APP。
2025 年,淘宝 Vision 在阿里巴巴西溪C区访客中心打造了首个“未来旗舰店”,为消费者带来更沉浸、更智能的购物体验。通过虚拟现实和人工智能技术,淘宝 Vision 将虚实完美融合,帮助商家有效降低线下经营成本,减少搭建、压货和装修费用,让线下购物更低成本、更丰富、更灵活。3D 人工智能数字人也在其中发挥重要作用。经过持续升级,3D 数字人将实现更精准的语音理解、更专业的导购知识,支持眼神交流、表情反馈和手势动作互动,为消费者带来更自然、更智能的 AI 购物体验。

未来蓝图:技术演进与生态拓展
从专业影棚到XR眼镜,从实验室算法到直播间互动,TaoAvatar 正将 3D 数字人技术推向临界点:凭借3D 重建算法突破,将建模成本和制作周期压缩至实时生成,更让数字人具备读懂微表情、自主决策的类人交互能力。这项技术已悄然融入淘宝 Vision 的商业实践,用每天用户的真实交互,验证了虚实融合的可行性。
当手机摄像头开始扫描人脸轮廓,当普通用户也能用一杯咖啡的预算定制专属数字分身,我们正清晰地看到——技术普惠的浪潮,正从 B 端走向 C 端。未来三年,随着3D重建大模型、AIGC编辑等技术的突破,结合多模态语音大模型赋能的毫秒级对话能力,3D 数字人将不再只是商业工具,而将成为每个人在数字世界的化身——既能随心切换服饰妆容参与虚拟社交,也能带着我们的思维习惯执行智能任务。
技术进化的轨迹总是充满惊喜。TaoAvatar 团队正深入攻克重建精度与驱动自然度的深水区:当数字人的发丝飘动能传递情绪温度,当 AI 驱动的微表情比真人更懂共情,或许我们会重新思考人与技术的关系。这不仅是工具的迭代,更是人类存在方式的演进——就像文字延伸了思想,机械拓展了肢体,3D 真人数字人将成为我们在虚实世界中自由穿梭的“第二存在”。

附录
TaoAvatar技术所有开源链接汇总:
-
TaoAvatar项目主页:https://pixelai-team.github.io/TaoAvatar
-
TalkBody4D数据集:https://huggingface.co/datasets/PixelAI-Team/TalkBody4D
-
GaussianTalker项目主页:https://pixelai-team.github.io/GaussianTalker/
-
MNN 端侧3D数字人AI对话项目:https://github.com/alibaba/MNN/tree/master/apps/Android/Mnn3dAvatar
-
MNN 端侧LLM大模型推理引擎:https://github.com/alibaba/MNN/tree/master
TaoAvatar技术目前获奖汇总:
-
被选为CVPR 2025 Highlight Paper,比例13.5% of the accepted papers
-
CVPR 2025 现场Demo邀请
-
CVPR 2025 Workshop on Photorealistic 3D Head Avatars (P3HA) 动态重建赛道冠军
-
CHINA3DV 2025 第四届中国三维视觉大会最佳技术候选(第三名)
-
CHINA3DV 2025 第四届中国三维视觉大会fasterforward(20/86)
-
CCIG 2025 中国图象图形大会 专题邀请

团队介绍
大淘宝技术Meta技术团队,目前负责面向消费场景的3D/XR基础技术建设和创新应用探索,创造以手机及XR 新设备为载体的消费购物新体验。团队在端智能、端云协同、商品三维重建、真人三维重建、3D引擎、XR引擎等方面有着深厚的技术积累,先后发布深度学习引擎MNN、商品三维重建工具Object Drawer、3D真人数字人TaoAvatar、端云协同系统Walle等。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。欢迎视觉算法、3D/XR引擎、深度学习引擎研发、终端研发等地方的优秀人才加入,共同走进3D数字新时代。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法


