广义优势估计的推导
总结
指数加权平均
对于一组数字 计算指数加权平均
, 其中i是下标. 那么有
把按照下标顺序代入,
多步时序差分误差
![]()
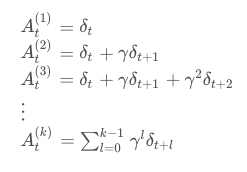
分别是t时刻的 一步误差, 两步误差, 三步误差, ... k步误差. 把这些步的误差倒过来代入指数加权公式,就得到了该时刻的GAE.
GAE的计算
考虑t时刻的无穷步误差的指数加权, 有
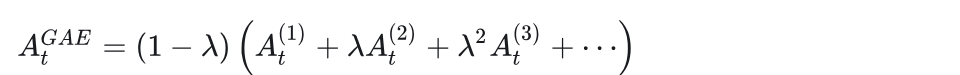
把代入,然后重新拆分得到
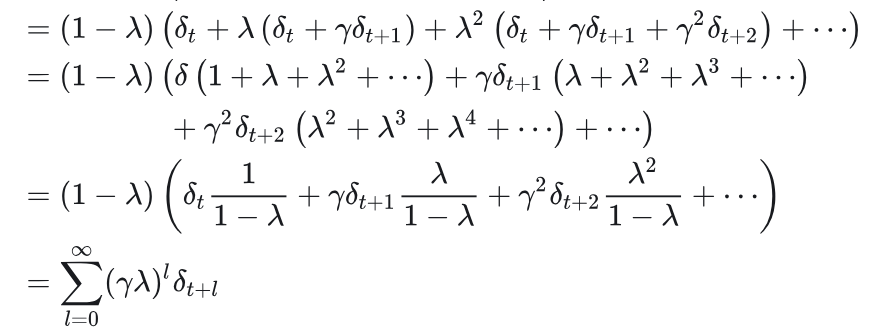
可见GAE的递推公式, 可以利用该公式, 从后往前一次性算出所有时刻的GAE.
def compute_gae_and_returns( rewards: torch.Tensor, values: torch.Tensor, next_values: torch.Tensor, dones: torch.Tensor, discount_rate: float, lambda_gae: float, ) -> Tuple[torch.Tensor, torch.Tensor]: advantages = torch.zeros_like(rewards) last_advantage = 0.0 n_steps = len(rewards) # 计算GAE for t in reversed(range(n_steps)): mask = 1.0 - dones[t] delta = rewards[t] + discount_rate * next_values[t] * mask - values[t] advantages[t] = delta + discount_rate * lambda_gae * last_advantage * mask last_advantage = advantages[t] # 返回给critic作为TD目标 returns_to_go = advantages + values return advantages, returns_to_go
