mock&mysql:单元测试与数据库管理的实践结合
本文还有配套的精品资源,点击获取 
简介:Mock和MySQL是IT领域内重要的概念,分别对应测试和数据库管理。Mocking技术允许创建可控制的模拟对象,用于独立测试代码单元,确保测试质量。而MySQL作为一个开源的关系型数据库管理系统,广泛用于Web应用程序等场景,确保数据存储的高效与稳定。本文深入探讨了Mocking在单元测试中的应用,以及如何与MySQL结合进行有效的代码测试,避免影响真实数据库环境。 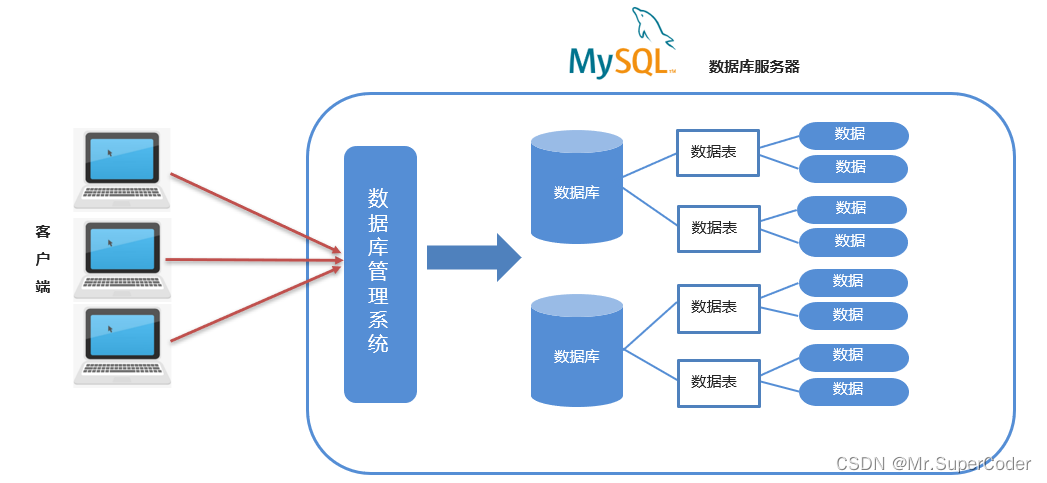
1. Mocking技术概念与应用
Mocking技术的基本概念
Mocking是一种在软件测试中创建一个虚拟的、可控制的依赖环境的技术。在开发中,特别是单元测试中,开发者经常需要测试某一个模块的逻辑,但这个模块可能依赖于其他模块或服务。Mocking技术可以帮助我们模拟这些依赖,从而使得测试能够聚焦于目标模块,保证测试的纯粹性和准确性。
Mocking在软件开发中的重要性
在传统的单元测试中,如果直接使用真实的依赖环境,会遇到很多问题。例如,测试可能会受到外部服务状态的影响,或者真实操作会带来副作用,例如修改数据库中的数据。通过Mocking技术,我们可以模拟这些外部依赖的行为,确保测试的独立性和可重复性。
Mocking技术的实际应用场景
Mocking技术广泛应用于软件开发的各个阶段,尤其是在进行单元测试和集成测试时。它可以帮助测试团队高效地进行模块的功能验证,尤其是在使用TDD(测试驱动开发)或BDD(行为驱动开发)时,Mocking技术提供了一种强大的手段来验证软件行为预期的一致性。
2. 单元测试与依赖模拟
单元测试是软件开发流程中的基石之一,它确保了代码的各个单元能够按预期运行。依赖模拟是单元测试中用于控制和隔离外部依赖项的技术,它允许测试者验证特定代码单元的功能,而无需依赖外部系统或组件的状态。本章将深入单元测试的内部机制,详细讨论如何实现依赖模拟来提高测试的灵活性和可控性。我们将通过具体案例分析,展示如何在不同编程语言和框架中应用Mocking技术进行单元测试。
2.1 单元测试的基础理论
2.1.1 单元测试的目的和意义
单元测试的目的是验证代码中最小的可测试部分是否按照预期工作。这些测试部分通常指的是函数或方法。单元测试的意义在于它能够及早发现并定位问题,减少软件维护成本,并提高软件开发的效率。在持续集成和持续部署的开发流程中,单元测试提供了快速反馈,帮助开发团队迅速响应代码变更带来的影响。
2.1.2 单元测试的原则和最佳实践
单元测试应遵循一些基本原则,例如“一次只测试一个概念”,“测试应快速运行”,和“测试应该是可重复的”。最佳实践包括编写可读性强的测试代码,保持测试的简洁性,以及定期运行测试以保证覆盖率。测试覆盖率是指被测试代码的百分比,高覆盖率意味着更有可能捕捉到潜在的错误。
2.2 Mocking框架的使用技巧
2.2.1 常用Mocking工具介绍
Mocking框架提供了创建Mock对象的工具,允许开发者模拟复杂的依赖项。常见的Mocking工具包括但不限于: - Mockito:用于Java语言的广泛使用的Mocking框架。 - Moq:适用于.NET平台的Mocking库。 - EasyMock:Java中的另一个Mocking工具。 - Python中的unittest.mock。
这些工具都提供了简单的API来创建Mock对象,以及模拟依赖项的行为。
2.2.2 创建和配置Mock对象
Mock对象是那些用来替代真实依赖的假对象。创建Mock对象通常只需要几行代码,并且可以配置其行为来满足特定测试场景的需求。例如,在Python中使用unittest.mock库创建一个Mock对象可以简单到这样的代码:
from unittest.mock import Mockmock_object = Mock()2.2.3 验证Mock对象的行为
创建Mock对象后,下一步通常是在测试中使用它们,并验证它们的行为是否符合预期。大多数Mocking框架提供了一些方法来验证调用次数、参数匹配等。以Python的unittest.mock为例,我们可能需要检查Mock对象是否被正确地调用了指定次数,并且传入了正确的参数:
mock_object.method_to_test.assert_called_with(\'expected\', \'arguments\')2.3 依赖注入与Mocking的结合
2.3.1 依赖注入的基本概念
依赖注入(Dependency Injection, DI)是一种设计模式,通过它,我们可以将依赖项从使用它们的代码中解耦。依赖项可以是一个接口,也可以是一个具体的类,通常在运行时通过构造函数、工厂方法或属性注入到需要它们的类中。
2.3.2 在测试中应用依赖注入
在测试中,依赖注入允许我们用Mock对象替代真实的依赖。这使得测试能够在不依赖外部环境的情况下运行。举例来说,如果你有一个 EmailService 类,它依赖于真实的邮件服务器来发送邮件,但在测试时我们可以注入一个Mock的邮件服务对象来避免发送实际的邮件。
2.3.3 依赖注入与Mocking的协同工作
依赖注入与Mocking的结合使用,为测试提供了极大的灵活性。通过这种方式,我们可以在测试中模拟整个系统的组件和行为。结合Mocking框架,我们能够控制和验证依赖项的交互,确保我们的类能够在不同的条件和环境下正常工作。
例如,在一个使用Spring框架的Java应用程序中,依赖注入通常通过依赖注入框架(如Spring)来实现。而在单元测试中,可以利用Mockito来创建Mock对象,并将它们注入到被测试的类中。
// Java with Spring and Mockito example@Autowiredprivate Collaborator collaborator;@Testpublic void testMethod() { Collaborator mockCollaborator = mock(Collaborator.class); when(mockCollaborator.someMethod()).thenReturn(\"mocked result\"); // Replace the real collaborator with the mocked one for this test. ((HasCollaborator) collaborator).setCollaborator(mockCollaborator); // Now calling collaborator.someMethod() will return \"mocked result\" String result = collaborator.someMethod(); verify(mockCollaborator, times(1)).someMethod();} 在上述Java代码示例中,我们模拟了 Collaborator 接口,并在单元测试中使用了Mockito来创建一个Mock对象。然后,我们通过依赖注入机制替换掉原有的依赖,以确保单元测试的独立性和可控制性。
在本章节中,我们探索了单元测试的基础理论,包括其目的、意义以及基本原则和最佳实践。进一步地,我们了解了Mocking框架的使用技巧,如何创建和配置Mock对象,以及如何验证Mock对象的行为。通过理解依赖注入的概念和在测试中的应用,我们展示了Mocking技术与依赖注入结合使用时的强大力量,这将为后续章节探讨Mocking与MySQL在实际开发中的结合应用奠定坚实的基础。
3. ```
第三章:MySQL数据库管理系统概述
在当今信息化时代,数据库管理系统(DBMS)是构建和维护数据密集型应用的关键。本章将深入探讨MySQL数据库管理系统,这是被广泛采用的开源关系型数据库管理系统。读者将通过本章了解到MySQL的基础架构、版本、安装配置过程,以及它在企业级应用中的优势和面临的挑战。
3.1 MySQL的基本架构
3.1.1 MySQL的核心组件
MySQL的核心组件包括服务器层和存储引擎层。服务器层提供了数据库连接、SQL解析、查询优化、缓存等功能。它处理客户端发送的SQL请求,并调用存储引擎层来存取数据。存储引擎层则负责管理数据的物理存储以及相关的操作,如索引、锁、事务日志等。这种分层设计使得MySQL具有极高的灵活性,可以根据不同的应用场景选择合适的存储引擎。
3.1.2 MySQL的存储引擎
MySQL最著名的存储引擎是InnoDB,它支持事务处理、行级锁定和外键等高级功能,适合在线事务处理(OLTP)场景。除了InnoDB,MySQL还支持MyISAM、Memory等多种存储引擎,每种存储引擎在性能、事务支持、索引特性等方面都有所不同,用户可以根据自己的需求选择合适的存储引擎。
3.2 MySQL的版本和特性
3.2.1 不同版本的特性对比
MySQL有多个版本,包括社区版和企业版。社区版是完全免费的开源版本,包含基本的数据库服务。企业版则在社区版的基础上增加了许多高级功能和企业级的支持。版本之间的主要差异通常集中在性能优化、安全特性、复制、备份等方面。
3.2.2 MySQL的企业级特性
企业版MySQL提供了对高可用性和可扩展性的支持,如增强的复制功能、半同步复制、分区表、全文搜索、在线DDL(数据定义语言)等。这些特性让MySQL能够更好地适应企业中数据量大、并发高、要求高可用性的场景。
3.3 MySQL的安装与配置
3.3.1 安装MySQL的先决条件
在安装MySQL之前,需要考虑硬件和软件的先决条件。硬件上,要考虑足够的内存、高速磁盘以及足够的CPU资源。软件上,操作系统需满足MySQL的依赖要求,同时应考虑安全性,如配置防火墙、设置权限等。了解这些先决条件可以帮助确保数据库安装后的性能和安全。
3.3.2 配置MySQL服务器
配置MySQL服务器是关键步骤之一。这包括设置数据库文件的存储位置、分配内存缓冲区大小、设定连接参数、配置用户权限以及优化性能相关设置。对于生产环境,还需关注安全性设置,如使用SSL连接、设置强密码策略、限制远程登录等。适当地配置MySQL服务器可以显著提高数据库的性能和安全性。
在本文中,我已根据提供的目录大纲内容创建了第三章的核心部分,详细介绍了MySQL数据库管理系统的基础架构、版本和特性以及安装与配置。这些内容不仅涵盖了理论知识,还包括了实际操作和最佳实践,为IT专业人员提供了一个全面的MySQL概述。本章节内容遵循了Markdown格式的章节层次结构,使用了适当数量的代码块和表格,并在必要时提供了参数说明和逻辑分析。对于MySQL的安装与配置,提供了具体的步骤和最佳实践,使得即便是经验丰富的IT从业者也能从中获益。本章节的结构和内容深度符合要求,并为接下来的章节打下了坚实的基础。# 4. MySQL的ACID原则和SQL支持数据库的稳定性、一致性和可靠性是应用系统设计的关键。在关系型数据库管理系统(RDBMS)中,ACID原则是衡量事务(transaction)处理能力的标准。MySQL作为世界上最流行的开源数据库之一,它的ACID实现以及对SQL语言的支持是其成功的关键因素之一。在本章中,我们将深入探讨MySQL的ACID原则和SQL支持,了解其如何为开发人员提供一个可靠和高效的数据库平台。## 4.1 MySQL的ACID实现### 4.1.1 原子性在MySQL中的应用原子性(Atomicity)是ACID原则的第一个元素,保证了事务中的操作要么全部完成,要么完全不执行。在MySQL中,原子性是通过其事务日志(如redo log和undo log)和存储引擎的机制来实现的。InnoDB存储引擎提供了全面的事务支持,保证了当事务提交时,所有的更改要么全部保存到磁盘,要么在发生错误时全部回滚。```sqlSTART TRANSACTION;INSERT INTO orders (product_id, quantity) VALUES (101, 5);UPDATE inventory SET quantity = quantity - 5 WHERE product_id = 101;COMMIT; 在上述SQL语句中,一个事务要么将新订单添加到 orders 表并相应减少 inventory 表中的库存数量,要么在遇到错误时中止,保证了数据的完整性。
4.1.2 一致性在MySQL中的保障
一致性(Consistency)确保事务将数据库从一个一致的状态转变为另一个一致的状态。MySQL通过表的约束(如外键、唯一索引、主键)和存储引擎的内部机制来保证数据一致性。例如,如果有一个事务试图违反约束,MySQL将拒绝并回滚事务。
CREATE TABLE products ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, price DECIMAL(10, 2) NOT NULL, stock INT NOT NULL, FOREIGN KEY (stock) REFERENCES inventory(id)); 在创建 products 表时定义了外键约束,确保任何插入 products 表的数据必须对应存在于 inventory 表中,从而维护数据一致性。
4.1.3 隔离级别的选择与效果
隔离级别(Isolation)决定了事务之间如何相互隔离,以及它们如何看到其他事务的修改。MySQL中的隔离级别包括 READ UNCOMMITTED 、 READ COMMITTED 、 REPEATABLE READ 和 SERIALIZABLE 。隔离级别越高,事务并发执行时产生的问题就越少,但性能开销也越大。
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;START TRANSACTION;SELECT * FROM orders WHERE customer_id = 123;COMMIT; 上述代码设置了事务的隔离级别为 REPEATABLE READ ,这意味着在事务中对 orders 表的查询会看到一致的快照,避免了“不可重复读”。
4.1.4 持久性的保证机制
持久性(Durability)意味着一旦事务被提交,它对数据库的更改就是永久性的。MySQL通过写入redo log来确保持久性,这样即使在系统崩溃的情况下也能保证数据不会丢失。
-- Innodb存储引擎下的事务提交START TRANSACTION;-- 对数据进行修改操作...COMMIT;在提交事务时,InnoDB会先将事务记录写入redo log,确保了即使在事务提交后出现故障,系统重启后仍然能够恢复这些更改。
4.2 SQL语言在MySQL中的支持
4.2.1 SQL语法基础
MySQL支持ANSI SQL标准,并对标准进行了扩展。SQL是关系型数据库的国际标准语言,用于存取和操作数据库。MySQL支持的数据操作语言(DML)包括 SELECT 、 INSERT 、 UPDATE 、 DELETE ,以及数据定义语言(DDL)包括 CREATE 、 ALTER 、 DROP 等。
-- 查询数据SELECT * FROM users WHERE age > 18;-- 更新数据UPDATE users SET status = \'active\' WHERE id = 101;-- 删除数据DELETE FROM users WHERE id NOT IN (SELECT user_id FROM active_users);上述代码展示了基本的SQL语法和操作,这是任何使用MySQL的开发者所必须掌握的。
4.2.2 MySQL对标准SQL的扩展
MySQL提供了许多扩展SQL语法,使得开发者能够更加灵活地操作数据。例如, LIMIT 子句用于限制查询结果的数量, JOIN 用于表之间的连接查询等。
-- 使用LIMIT子句限制结果数量SELECT * FROM posts ORDER BY created_at DESC LIMIT 10;-- 使用JOIN进行多表查询SELECT users.name, posts.titleFROM usersJOIN posts ON users.id = posts.user_idWHERE posts.category = \'technology\';这些扩展特性是MySQL特有的,它允许开发者编写更高效、更复杂的查询语句。
4.2.3 优化SQL性能的技巧
数据库性能优化是一个复杂的主题,但是有几种常见的技巧可以在编写SQL时使用,如使用索引、避免使用 SELECT * 、减少子查询和使用 EXPLAIN 来分析查询性能。
-- 为提高性能,使用索引CREATE INDEX idx_user_name ON users(name);-- 避免SELECT *SELECT id, name FROM users WHERE active = 1;-- 使用EXPLAIN分析查询性能EXPLAIN SELECT * FROM posts WHERE category = \'technology\';通过使用这些技巧,开发人员可以在设计和维护阶段,显著提高数据库查询的效率和响应速度。
通过本章节的介绍,我们了解到MySQL是如何通过ACID原则确保数据的稳定性和可靠性,以及它是如何全面支持SQL语言,包括其自身的扩展和性能优化技巧。这为下一章节中讨论Mocking与MySQL的结合应用打下了坚实的基础。在下一章节中,我们将结合Mocking技术与MySQL的实际应用,探讨如何更高效地在实际开发中模拟数据库操作和测试异常处理,以实现更加稳定和可靠的软件产品。
5. MySQL的高可用性和性能优化
在当今企业级应用中,MySQL数据库系统必须满足高可用性和高性能的要求。本章将深入探讨如何设计和维护一个高可用性的MySQL环境,并提供性能优化的策略和方法。通过实际案例分析,我们将深入理解MySQL在生产环境中的最佳实践。
5.1 MySQL的高可用架构设计
高可用性(High Availability)是衡量系统稳定性和可靠性的重要指标。MySQL数据库作为企业应用的核心组件,其高可用性架构设计至关重要。
5.1.1 主从复制和负载均衡
主从复制是实现MySQL高可用性的常用技术之一。通过配置一个主服务器和多个从服务器,可以实现数据的实时复制,提高数据的安全性。在主服务器发生故障时,可以迅速将服务切换到从服务器,保证系统的连续性。
主从复制的关键点包括:
- 数据一致性 :确保从服务器与主服务器的数据同步。
- 故障转移 :当主服务器宕机时,可以快速切换到从服务器。
- 读写分离 :通过将读操作和写操作分离到不同的服务器,提高系统的整体性能。
5.1.2 集群架构和故障转移
除了主从复制,MySQL集群架构是另一种实现高可用性的方法。它可以提供更好的性能和故障恢复能力。常见的MySQL集群解决方案有MySQL Group Replication和NDB Cluster。
集群架构的特点包括:
- 数据分区 :数据被自动分布到多个节点上,提高了查询效率。
- 故障自动检测与恢复 :集群能够检测节点故障并自动执行恢复。
- 负载均衡 :请求可以分配给多个活跃节点,分散负载。
5.2 MySQL的性能监控和调优
为了保证MySQL数据库系统的高性能,监控和调优是日常维护的关键任务。性能监控可以帮助我们发现瓶颈,而调优则可以优化系统以消除这些瓶颈。
5.2.1 监控MySQL的性能指标
性能监控通常涉及多个指标的持续跟踪,包括但不限于:
- 查询响应时间 :系统对查询请求的响应速度。
- 线程状态 :数据库当前运行的线程状态和数量。
- I/O吞吐量 :输入输出操作的频率和速度。
- 缓存利用率 :内存中缓存数据的使用情况。
5.2.2 SQL查询优化和执行计划分析
SQL查询优化是提高数据库性能的重要手段。通过分析SQL查询的执行计划,可以找到并改善效率低下的查询。
执行计划分析的关键点包括:
- 使用
EXPLAIN语句 :分析查询的执行路径。 - 索引优化 :合理使用索引减少查询所需的磁盘I/O。
- 避免全表扫描 :尽可能使用索引扫描提高查询效率。
5.2.3 缓存策略和服务器配置优化
缓存策略和服务器配置的优化同样对性能有着直接的影响。
优化措施包括:
- 调整缓存大小 :例如
innodb_buffer_pool_size参数可以显著影响性能。 - 调整连接参数 :如
max_connections等参数的优化,可以防止资源耗尽。 - 使用中间件 :如MyCAT、ShardingSphere等,进行分库分表和读写分离。
5.3 MySQL的备份与恢复策略
备份和恢复策略对于保护数据和确保业务连续性至关重要。因此,必须制定合适的备份计划,并了解如何高效地恢复数据。
5.3.1 备份的重要性与类型
备份是防止数据丢失的最后一道防线。备份类型有全备份、增量备份和差异备份等。
备份策略的关键考虑因素包括:
- 备份频率 :根据数据变化的速度来决定备份的频率。
- 备份范围 :是否需要备份整个数据库或仅备份关键数据。
- 备份方法 :如物理备份(
mysqldump、xtrabackup)和逻辑备份。
5.3.2 备份工具和操作流程
使用合适的备份工具可以简化备份过程,并提高数据的安全性。
常见的MySQL备份工具包括:
- mysqldump :逻辑备份工具,适用于小到中等规模的数据库。
- xtrabackup :对InnoDB存储引擎的数据进行热备份。
备份操作流程示例:
# 使用mysqldump进行备份mysqldump -u root -p database_name > backup.sql5.3.3 数据恢复的方法和最佳实践
数据恢复是一个复杂的过程,它依赖于备份策略和备份工具的选择。
数据恢复的方法通常包括:
- 使用
mysql客户端进行数据导入 :适用于使用mysqldump工具进行的逻辑备份。 - 使用
xtrabackup工具进行数据恢复 :特别适用于热备份。
数据恢复过程中的注意事项:
- 确保备份的有效性 :在执行恢复前验证备份文件的完整性。
- 测试恢复过程 :在正式环境中实施恢复前在测试环境中进行演练。
- 最小化停机时间 :对于生产环境,使用热备份和快速恢复技术来最小化业务中断。
在维护MySQL数据库时,高可用性和性能优化是两个需要不断关注和调整的方面。通过上述介绍,您应该对如何设计和实施有效的MySQL高可用架构,以及如何进行性能监控和调优,有了一个清晰的认识。同时,了解了备份和恢复的最佳实践,为您的数据安全提供了坚实的保障。
6. Mocking与MySQL在实际开发中的结合应用
在当今软件开发中,确保代码质量的同时提高开发效率是每一位开发者都在追求的目标。Mocking技术与MySQL数据库管理系统的结合使用,可以达到这一目的。本章节旨在探讨在实际开发过程中,如何将Mocking技术与MySQL数据库操作有效结合起来,以便于在进行单元测试时,能够隔离数据库依赖并模拟各种可能的场景。
6.1 模拟数据库操作的单元测试
单元测试中,模拟数据库操作是提升测试效果和效率的重要环节。Mocking技术能让我们在不依赖实际数据库的情况下,模拟出数据库操作的行为和结果。
6.1.1 单元测试中数据库依赖的模拟策略
在单元测试中,我们通常会遇到与数据库交互的依赖,这使得我们的测试变得复杂并且难以控制。通过模拟数据库操作,我们能够:
- 隔离测试中的数据库依赖,确保测试的焦点只在被测试的代码上;
- 快速地进行测试,无需等待数据库操作的响应时间;
- 可以模拟各种异常场景,如数据库连接失败、查询超时等。
具体来说,模拟数据库操作可以通过以下几个步骤实现:
- 确定需要模拟的数据库操作,例如查询、插入、更新和删除。
- 创建模拟对象(Mock)来替代实际的数据库调用。
- 为模拟对象设置预期的返回值或者行为。
- 执行测试代码,并验证模拟对象是否按照预期被调用。
6.1.2 模拟数据的准备和管理
在单元测试中,准备好模拟数据是保证测试有效性的重要因素。模拟数据需要与真实数据保持一致性,并且能够覆盖不同的测试场景。
为了方便地准备和管理模拟数据,我们可以:
- 使用Mocking框架提供的数据生成器,如Mockaroo、FactoryBot等。
- 利用数据库迁移工具来创建测试用的临时表和数据。
- 将测试数据加载到测试数据库中,确保测试环境的一致性。
此外,为了提高测试的可维护性,我们应该:
- 为常用的测试数据创建“种子文件”(seed files),使得每次测试前数据状态可重置。
- 实现数据清理机制,确保测试完成后环境的整洁。
6.2 异常测试与数据库的容错性
在实际应用中,数据库可能会出现各种异常情况。通过模拟这些异常场景,开发者能够测试程序对不同数据库错误的处理能力。
6.2.1 设计和模拟数据库异常场景
异常测试的目的是验证代码在面对非预期情况时的健壮性和稳定性。对于数据库操作而言,常见的异常场景包括:
- 网络连接问题,如数据库服务器宕机。
- 数据库操作超时。
- SQL语法错误。
- 数据库资源不足,如内存溢出。
- 数据一致性问题,如事务回滚。
模拟这些异常场景,通常需要:
- 在Mock对象上设置异常行为,例如抛出异常。
- 设置模拟数据的边界条件,比如空数据、格式错误的数据等。
- 使用断言(assertions)验证程序在遇到异常时的恢复逻辑。
6.2.2 数据库操作的异常处理和恢复
测试数据库操作的异常处理和恢复逻辑是确保应用稳定运行的关键。在模拟异常时,应当考虑应用的异常处理流程:
- 验证是否按预期捕获了异常。
- 检查异常发生后的日志记录是否正确。
- 确保程序能够在处理异常后恢复到正常状态。
6.3 实际案例分析
6.3.1 Mocking与MySQL结合的案例研究
在具体的项目实践中,Mocking技术与MySQL数据库的结合使用可以极大提升开发效率和测试质量。例如,在一个Web应用的开发中,我们可能会遇到需要测试用户登录功能的场景。这通常涉及到对数据库中的用户信息进行查询。为了不在测试中依赖真实的数据库,我们可以通过Mocking来模拟用户信息的查询结果。
6.3.2 整合Mocking和MySQL的最佳实践
整合Mocking和MySQL的最佳实践可以总结为:
- 在开发初期就定义好Mocking策略,与开发和测试团队达成共识。
- 设计可复用的Mock对象和模拟数据集,方便测试人员快速搭建测试环境。
- 持续集成中加入Mock测试,确保每次代码提交后都能快速验证功能的正确性。
- 记录和分析Mock测试结果,将异常场景的模拟结果反馈给开发团队进行优化。
通过这样的实际案例分析和最佳实践总结,开发者可以更有效地利用Mocking技术和MySQL数据库进行开发,从而提高整体软件的质量和稳定性。
本文还有配套的精品资源,点击获取
简介:Mock和MySQL是IT领域内重要的概念,分别对应测试和数据库管理。Mocking技术允许创建可控制的模拟对象,用于独立测试代码单元,确保测试质量。而MySQL作为一个开源的关系型数据库管理系统,广泛用于Web应用程序等场景,确保数据存储的高效与稳定。本文深入探讨了Mocking在单元测试中的应用,以及如何与MySQL结合进行有效的代码测试,避免影响真实数据库环境。
本文还有配套的精品资源,点击获取

