开源测试工具 [jvm-sandbox-repeater 学习笔记][原理说明篇] 2 回放流程
2.1 回放流程图
回放流程,是从用户通过请求 repeater-console 的回放接口开始的,然后 repeater-console 通过调用 repeater 提供的回放任务接收接口下发回放任务。repeater 在执行回放任务的过程中,会通过根据录制记录的信息,构造相同的请求,对被挂载的任务进行请求,并跟踪回放请求的处理流程,以便记录回放结果以及执行 mock 动作。
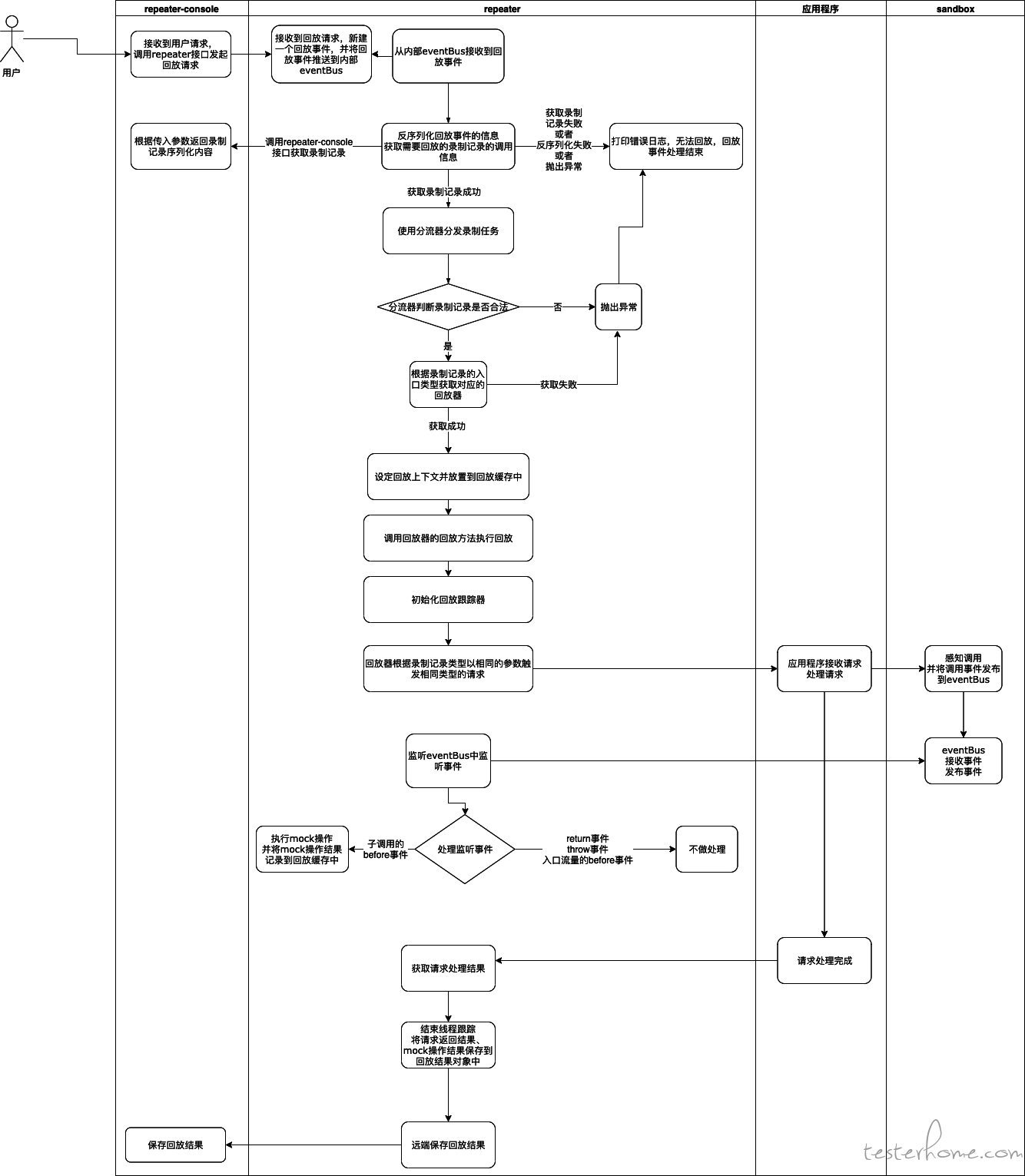
# 2.2 回放过程步骤的源码解析
整个回放过程比较复杂,以下将分为几个大流程来进行分析:
- 回放请求的处理与回放任务的分发
- 回放器的回放触发与回放结果记录
- 回放过程中的事件处理
2.2.1 回放请求的处理与回放任务的分发
2.2.1.1 回放请求的处理
回放请求最初的处理是在RepeaterModule#repeat方法。
这个方法前面加了@Command注解,使之可以通过 http 接口的形式供外部调用。
这个方法中主要是接收外部的回放请求,校验请求参数,请求参数校验通过后会将参数拼接成一个回放事件 RepeatEvent,发布到 repeater 内部的 EventBus 中。
/** * 回放http接口 * * @param req 请求参数 * @param writer printWriter */ @Command(\"repeat\") public void repeat(final Map req, final PrintWriter writer) { try { String data = req.get(Constants.DATA_TRANSPORT_IDENTIFY); if (StringUtils.isEmpty(data)) { writer.write(\"invalid request, cause parameter {\" + Constants.DATA_TRANSPORT_IDENTIFY + \"} is required\"); return; } RepeatEvent event = new RepeatEvent(); Map requestParams = new HashMap(16); for (Map.Entry entry : req.entrySet()) { requestParams.put(entry.getKey(), entry.getValue()); } event.setRequestParams(requestParams); EventBusInner.post(event); writer.write(\"submit success\"); } catch (Throwable e) { writer.write(e.getMessage()); } }RepeatEvent 发布到 EventBus 后,将被RepeatSubscribeSupporter捕获并在onSubscribe方法中进行处理。
在这个处理过程中,会将 RepeatEvent 的参数进行反序列化,获取回放相关的录制记录的信息,并通过这些信息从 repeater-console 拉取对应的录制记录详情(RecordModel)。
当需要回放的录制记录获取成功后,则是用默认流量分发器DefaultFlowDispatcher进行分发。
当获取录制记录失败/反序列化失败/分发回放任务返回报错时,都会打印日志,并结束回放任务处理。
@Override public void onSubscribe(RepeatEvent repeatEvent) { Map req = repeatEvent.getRequestParams(); try { final String data = req.get(Constants.DATA_TRANSPORT_IDENTIFY); if (StringUtils.isEmpty(data)) { log.info(\"invalid request cause meta is null, params={}\", req); return; } log.info(\"subscribe success params={}\", req); final RepeatMeta meta = SerializerWrapper.hessianDeserialize(data, RepeatMeta.class); RepeaterResult pr = StandaloneSwitch.instance().getBroadcaster().pullRecord(meta); if (pr.isSuccess()){ DefaultFlowDispatcher.instance().dispatch(meta, pr.getData()); } else { log.error(\"subscribe replay event failed, cause ={}\", pr.getMessage()); } } catch (SerializeException e) { log.error(\"serialize failed, req={}\", req, e); } catch (Exception e) { log.error(\"[Error-0000]-uncaught exception occurred when register repeat event, req={}\", req, e); } }}2.2.1.2 回放任务的分发
回放任务的分发由DefaultFlowDispatcher#dispatch方法实现。
在这里主要是针对回放任务的信息进行校验,无法通过校验的回放任务信息会抛出错误到上层。
通过校验的回放任务,则会
- 根据回放信息初始化回放上下文信息,并存放到回放缓存中。
- 根据回放任务的入口调用类型,获取对应的 Repeater 进行回放处理。
@Override public void dispatch(RepeatMeta meta, RecordModel recordModel) throws RepeatException { if (recordModel == null || recordModel.getEntranceInvocation() == null || recordModel.getEntranceInvocation().getType() == null) { throw new RepeatException(\"invalid request, record or root invocation is null\"); } JSONObject.toJSONString(recordModel.getEntranceInvocation().getType().name())); Repeater repeater = RepeaterBridge.instance().select(recordModel.getEntranceInvocation().getType()); if (repeater == null) { throw new RepeatException(\"no valid repeat found for invoke type:\" + recordModel.getEntranceInvocation().getType().name()); } RepeatContext context = new RepeatContext(meta, recordModel, TraceGenerator.generate()); // 放置到回放缓存中 RepeatCache.putRepeatContext(context); repeater.repeat(context); }2.2.2 回放器的请求触发与回放结果记录
根据不同的回放调用类型,回放任务会被不同的 Repeater 执行。
目前已实现功能的 Repeater 有两种:JavaRepeater、HttpRepeater。这两个 Repeater 都继承了 AbstractRepeater 类。AbstractRepeater 实现了回放器中回放执行和记录的主要流程逻辑,而具体插件则根据需要实现了 executeRepeat 触发回放、getType 调用类型、identity 回放器标识的方法。
所以从 AbstractRepeater 可以了解到回放结果记录、回放结果处理的实现,而从插件的 Repeater 可以了解到请求触发的机制。
2.2.2.1 回放结果记录
回放任务执行、回放结果记录的实现逻辑在AbstractRepeater#repeat中实现。但是调用的时候,实际上是通过各个插件的回放器实例来调用的。
当开始执行回放任务时,会根据回放上下文以及当前 repeater 的应用信息初始化回放结果记录 RepeaterModel 的实例。
初始化回放结果记录后,初始化回放线程跟踪并触发回放请求并获取回放请求返回的结果。
获取回放请求返回的结果后,停止线程跟踪,将回放结果以及当前的一些状态信息保存到回放结果记录的实例中。
最后通过调用消息投递器的 broadcastRepeat 方法将回放结果记录序列化后上传到 repeater-console 保存。
PS:消息投递器当前支持两种模式,在 standalone 模式下,保存到本地文件;在非 standalone 模式下上传到 repeater-console。
@Override public void repeat(RepeatContext context) { Stopwatch stopwatch = Stopwatch.createStarted(); ApplicationModel am = ApplicationModel.instance(); RepeatModel record = new RepeatModel(); record.setRepeatId(context.getMeta().getRepeatId()); record.setTraceId(context.getTraceId()); record.setAppName(am.getAppName()); record.setEnvironment(am.getEnvironment()); record.setHost(am.getHost()); record.setStarTime(new Date()); try { // 根据之前生成的traceId开启追踪 Tracer.start(context.getTraceId()); // before invoke advice RepeatInterceptorFacade.instance().beforeInvoke(context.getRecordModel()); Object response = executeRepeat(context); // after invoke advice RepeatInterceptorFacade.instance().beforeReturn(context.getRecordModel(), response); stopwatch.stop(); record.setEndTime(new Date()); record.setCost(stopwatch.elapsed(TimeUnit.MILLISECONDS)); record.setFinish(true); record.setResponse(response); record.setMockInvocations(RepeatCache.getMockInvocation(context.getTraceId())); } catch (Exception e) { log.error(\"repeat fail\", e); stopwatch.stop(); record.setCost(stopwatch.elapsed(TimeUnit.MILLISECONDS)); record.setResponse(e); } finally { Tracer.end(); } sendRepeat(record); }2.2.2.2 回放请求的触发
回放请求的触发对应的方法是各个插件的 Repeater 的 executeRepeat 方法。不同插件或者说不同的调用类型的请求触发的方式是不同的。但是设计思路都是一致的:从录制记录中获取需要触发的请求的路径(url/方法名)和请求参数,拼接请求,然后通过各自的协议请求方式去触发本机的服务或者说当前挂载 repeater 的应用。
这里以分别以 httpRepeater 和 JavaRepeater 为例进行分别说明。
下面是 JavaRepeater 的回放触发。这个回放触发主要做了几个步骤:
- 从回放上下文中获取到入口的调用记录
- 从入口调用记录的 Indentity 中获取回放需要的方法名、类名、请求参数。
- 通过类名获取到应用中的实例对象、通过类名、方法名、请求参数类型获取对应的方法实例。
- 通过反射的方式调用对应的方法、传入参数触发回放。
@Override protected Object executeRepeat(RepeatContext context) throws Exception { Invocation invocation = context.getRecordModel().getEntranceInvocation(); Identity identity = invocation.getIdentity(); Object bean = SpringContextAdapter.getBeanByType(identity.getLocation()); if (bean == null) { throw new RepeatException(\"no bean found in context, className=\" + identity.getLocation()); } if (invocation.getType().equals(this.getType())) { throw new RepeatException(\"invoke type miss match, required invoke type is: \" + invocation.getType()); } String[] array = identity.getEndpoint().split(\"~\"); // array[0]=/methodName String methodName = array[0].substring(1); ClassLoader classLoader = ClassloaderBridge.instance().decode(invocation.getSerializeToken()); if (classLoader == null) { classLoader = ClassLoader.getSystemClassLoader(); } // fix issue#9 int.class基本类型被解析成包装类型,通过java方法签名来规避这类问题 // array[1]=javaMethodDesc MethodSignatureParser.MethodSpec methodSpec = MethodSignatureParser.parseIdentifier(array[1]); Class[] parameterTypes = MethodSignatureParser.loadClass(methodSpec.getParamIdentifiers(), classLoader); Method method = bean.getClass().getDeclaredMethod(methodName, parameterTypes); // 开始invoke return method.invoke(bean, invocation.getRequest()); }下面是 httpRepeater 的回放触发。这个回放触发主要做了几个步骤:
- 从回放上下文中获取到入口的调用记录,并将这个 Invocation 转义成 HttpInvication 类型。
- 从 HttpInvication 中获取回放需要的 urlPath、请求端口、header、以及请求参数、请求方法(当前只支持 GET/POST)并组装成一个请求。
- 发起这个 http 请求。
@Override protected Object executeRepeat(RepeatContext context) throws Exception { Invocation invocation = context.getRecordModel().getEntranceInvocation(); if (!(invocation instanceof HttpInvocation)) { throw new RepeatException(\"type miss match, required HttpInvocation but found \" + invocation.getClass().getSimpleName()); } HttpInvocation hi = (HttpInvocation) invocation; Map extra = new HashMap(2); // 透传当前生成的traceId到http线程 HttpStandaloneListener#initConetxt extra.put(Constants.HEADER_TRACE_ID, context.getTraceId()); // 直接访问本机,默认全都走http,不关心protocol StringBuilder builder = new StringBuilder() .append(\"http\") .append(\"://\") .append(\"127.0.0.1\") .append(\":\") .append(hi.getPort()) .append(hi.getRequestURI()); String url = builder.toString(); Map headers = rebuildHeaders(hi.getHeaders(), extra); HttpUtil.Resp resp = HttpUtil.invoke(url, hi.getMethod(), headers, hi.getParamsMap(), hi.getBody()); return resp.isSuccess() ? resp.getBody() : resp.getMessage(); }PS:从 JavaRepeater 和 HttpRepeater 的回放触发的实现中,会发现获取回放请求所需信息时,虽然都是从回放上下文获取的,但获取的字段却不一样。这个差异主要是插件在录制时,处理参数、identity 拼接的方法不同、甚至是 EventListener 不同导致的。说明回放器的设计是需要包括录制过程时对于请求相关信息的处理方案的。
2.2.3 回放过程中的事件处理
回顾一下 02 原理分析篇的1.2.4 Before事件处理和1.2.5 Return事件处理/ Throw事件处理篇,就会发现在回放过程中,DefaultEventListner 处理的方法似乎非常简单粗暴:
- throw/return 事件不做处理
- before 事件直接交给插件调用处理器执行 mock,并且从注释中也能了解到,只对子调用事件执行 mock。
// 回放流量;如果是入口则放弃;子调用则进行mock if (RepeatCache.isRepeatFlow(Tracer.getTraceId())) { processor.doMock(event, entrance, invokeType); return; }所以在回放过程的事件中,我们以AbstractInvocationProcessor#doMock方法为起点进行分析。
2.2.3.1 回放的 mock 流程
与AbstractRepeater#repeat相似,执行回放的 mock 的流程实现逻辑基本在AbstractInvocationProcessor#doMock实现,但是实际调用时,是通过插件中各自的 Processor 的实例进行调用的。
当开始执行回放 mock 时,会先获取回放上下文的信息。
根据回放上下文的信息,判断是否跳过 mock 的执行。
当需要执行 mock 时,会根据回放上下文中的信息拼接出 MockRequest
通过 mock 策略计算获取 MockResponse
根据 MockResponse 的状态进行不同的操作:
- 当 MockResponse 获取到的结果是 return 正常内容时,就会抛出一个终止当前调用操作并返回当前的返回结果 ProcessControlException,用来阻挡这个需要 mock 的方法的实际调用。
- 当 MockResponse 获取到的结果是返回一个执行异常时,就会抛出一个终止当前调用操作并抛出异常的 ProcessControlException,用来阻挡这个需要 mock 的方法的实际调用。
- 只有当 MockResponse 的状态是 skip 时,则不对这个调用事件做任何处理,调用会实际发生,其他任何状态都会通过抛出 ProcessControlException 来阻挡这个事件的实际调用。
PS:ProcessControlException 我目前只知道他能够在回放过程中中止调用动作,但是在整个过程如何生效的,还没看明白,这个得了解到 jvm-sandbox 对于 ProcessControlException 的处理逻辑。
@Overridepublic void doMock(BeforeEvent event, Boolean entrance, InvokeType type) throws ProcessControlException { /* * 获取回放上下文 */ RepeatContext context = RepeatCache.getRepeatContext(Tracer.getTraceId()); /* * mock执行条件 */ if (!skipMock(event, entrance, context) && context != null && context.getMeta().isMock()) { try { /* * 构建mock请求 */ final MockRequest request = MockRequest.builder() .argumentArray(this.assembleRequest(event)) .event(event) .identity(this.assembleIdentity(event)) .meta(context.getMeta()) .recordModel(context.getRecordModel()) .traceId(context.getTraceId()) .type(type) .repeatId(context.getMeta().getRepeatId()) .index(SequenceGenerator.generate(context.getTraceId())) .build(); LogUtil.debug(\"doMock.identity={}\",JSONObject.toJSONString(request.getIdentity(), SerializerFeature.IgnoreNonFieldGetter)); /* * 执行mock动作 */ final MockResponse mr = StrategyProvider.instance().provide(context.getMeta().getStrategyType()).execute(request); /* * 处理策略推荐结果 */ switch (mr.action) { case SKIP_IMMEDIATELY: break; case THROWS_IMMEDIATELY: ProcessControlException.throwThrowsImmediately(mr.throwable); break; case RETURN_IMMEDIATELY: ProcessControlException.throwReturnImmediately(assembleMockResponse(event, mr.invocation)); break; default: ProcessControlException.throwThrowsImmediately(new RepeatException(\"invalid action\")); break; } } catch (ProcessControlException pce) { throw pce; } catch (Throwable throwable) { ProcessControlException.throwThrowsImmediately(new RepeatException(\"unexpected code snippet here.\", throwable)); } }}从AbstractInvocationProcessor#doMock方法中可以看到,执行 mock 动作的关键性代码是这一行
final MockResponse mr = StrategyProvider.instance().provide(context.getMeta().getStrategyType()).execute(request);从这里可以看到回放的时候会从上下文中的 RepeatMeta 中获取策略类型并执行 mock。
StrategyProvider.instance().provide(context.getMeta().getStrategyType())方法返回的是一个 MockStrategy 对象,即 mock 策略对象。而这个对象的 execute 方法点进去看,是跳转到了AbstractMockStrategy#execute方法中。
与之前的 repeater 的实现套路类似,这个方法中实现的是执行 mock 的整体流程,但是实际上是由实现了 MockStrategy 接口的实现类实例进行调用的。
在执行 mock 的过程中,主要是初始化 mock 调用信息保存到回放缓存,并通过匹配策略的 select 方法,从录制记录的子调用列表中,查询到与当前调用入参和方法名一致的子调用记录,并针对将查询得出的子调用 response 或者 throwable 组装到 MockResponse 中。
PS:在这个过程中,提供了在匹配子调用前干涉的机会,实现对应接口即可在匹配前修改调用的参数等信息。
@Override public MockResponse execute(final MockRequest request) { MockResponse response; try { /* * before select hook; */ MockInterceptorFacade.instance().beforeSelect(request); /* * do select */ SelectResult select = select(request); Invocation invocation = select.getInvocation(); MockInvocation mi = new MockInvocation(); mi.setIndex(SequenceGenerator.generate(request.getTraceId() + \"#\")); mi.setCurrentUri(request.getIdentity().getUri()); mi.setCurrentArgs(request.getArgumentArray()); mi.setTraceId(request.getTraceId()); mi.setCost(select.getCost()); mi.setRepeatId(request.getRepeatId()); // add mock invocation RepeatCache.addMockInvocation(mi); // matching success if (select.isMatch() && invocation != null) { response = MockResponse.builder() .action(invocation.getThrowable() == null ? Action.RETURN_IMMEDIATELY : Action.THROWS_IMMEDIATELY) .throwable(invocation.getThrowable()) .invocation(invocation) .build(); mi.setSuccess(true); mi.setOriginUri(invocation.getIdentity().getUri()); mi.setOriginArgs(invocation.getRequest()); } else { response = MockResponse.builder() .action(Action.THROWS_IMMEDIATELY) .throwable(new RepeatException(\"no matching invocation found\")).build(); } /* * before return hook; */ MockInterceptorFacade.instance().beforeReturn(request, response); } catch (Throwable throwable) { log.error(\"[Error-0000]-uncaught exception occurred when execute mock strategy, type={}\", type(), throwable); response = MockResponse.builder(). action(Action.THROWS_IMMEDIATELY) .throwable(throwable) .build(); } return response; }2.2.3.2 回放的 mock 策略
在 mock 执行过程中,执行 mock 的流程在AbstractMockStrategy#execute中实现,而不同的 mock 匹配策略的匹配算法差异,则在 MockStrategy 的实现类中,各自重写select方法来实现。
当前的官方文档提供了两个 MockStrategy 的实现类,DefaultMockStrategy和ParameterMatchMockStrategy。其中DefaultMockStrategy是默认返回不匹配结果的,所以我们一般流程使用的 mock 策略是ParameterMatchMockStrategy。
简单说说ParameterMatchMockStrategy#select方法的实现逻辑重点,实现细节可以看代码去更进一步理解。
- 从被回放的录制记录中获取子调用列表 subInvocations
- 根据 Invocation 中的 identity 字段过滤得到跟本次 mock 的调用相同的子调用列表 target。
- 当 target 列表为空时,返回一个状态是未匹配且调用结果是空的选择结果。
- 遍历子调用列表 targer,通过比对本次 mock 调用的入参和 target 列表中每一个子调用的入参的序列化的自串串,得到一个相似度的数值。遍历过程中,当相似度合格(相似度计算结果大于或等于 1)的时候,则停止循环,从录制记录中删除该子调用,并以该子调用构造选择结果返回,并且选择结果的返回状态是已匹配的。
- 当 target 列表遍历完成后,仍然没有相似度合格的子调用,则以相似度最大的子调用构造选择结果返回,此时选择结果返回的状态是未匹配。
- 而在外部使用这个选择结果的时候,需要判断是否有
那我们是怎么决定想要使用的 MockStrategy 类型的呢?
从前文可知,回放的 mock 策略是根据回放上下文中的 RepeatMeta 里面来选择的。在向上回溯会发现 RepeatMeta 是从 repeater-console 在推送回放任务的时候传过来的。再一路跟随代码调用搜索,会发现在
AbstractRecordService#repeat方法中,初始化 RepeatMeta 就写死了PARAMETER_MATCH。
protected RepeaterResult repeat(Record record, String repeatId, String host, String port) { String repeatUrl = String.format(\"http://%s:%s%s\", host, port, repeatUri); RepeatMeta meta = new RepeatMeta(); meta.setAppName(record.getAppName()); meta.setTraceId(record.getTraceId()); meta.setMock(true); meta.setRepeatId(StringUtils.isEmpty(repeatId) ? TraceGenerator.generate() : repeatId); meta.setStrategyType(MockStrategy.StrategyType.PARAMETER_MATCH); Map requestParams = new HashMap(2); try { requestParams.put(Constants.DATA_TRANSPORT_IDENTIFY, SerializerWrapper.hessianSerialize(meta)); } catch (SerializeException e) { return RepeaterResult.builder().success(false).message(e.getMessage()).build(); } HttpUtil.Resp resp = HttpUtil.doPost(repeatUrl, requestParams); if (resp.isSuccess()) { return RepeaterResult.builder().success(true).message(\"operate success\").data(meta.getRepeatId()).build(); } return RepeaterResult.builder().success(false).message(\"operate failed\").data(resp).build();}
