人脸识别之-ArcFace
写在前面
曾经有过一段时间的工作是围绕着人脸识别展开的,也形形色色做了不少这方面的工作,包括训练,部署和SDK封装之类的,也做过蒸馏,量化等尝试,发现再怎么做,人脸识别的瓶颈还是再哪里,好不容易调出来一版比较满意的版本,在经过现场和不同环境的使用后,得到的反馈是:还是不行啊。没办法,实验室里面的数据都是99%以上的识别率,外面的人都是先入为主了,他们不知道有折扣这么一说,牢骚归牢骚,总的来说人脸识别也算是人工智能/深度学习领域一个较为成熟,落地较多的一种应用,现在的很多场合都有这个技术的应用,相信现在的人都有用过。在这里我们就简单了解一下人脸识别中的其中一个方法-ArcFace。
基本概念
在这个章节里有几个基本概念是需要了解的。
1 人脸识别包含哪些步骤,有人嘴里经常说人脸识别,但不知道这不是一个单一的技术,它包含了,人脸检测/定位,人脸对齐,人脸特征提取,人脸特征比对(有的地方也叫人脸相似度计算)四个过程,总的来说,人脸识别就是用来分辨这两张脸属于张三是张三,张三不是李四的一个过程。当然了,除了前面提到的四个过程,还有要给人脸活体检测,这个在个人看来,是个伪命题,但在实际应用中又十分重要。
2 什么是人脸识别中的特征嵌入(embedding)?特征嵌入是将人脸图像映射到一个低维向量空间的过程,在这个空间中,同一个人的不同图像应该距离较近,不同人的图像应该距离较远。这也是人脸识别中最重要的一个重要工作,就是把一个人的特征抽象化后映射到一个低维的空间里,这样在后续的比对过程只需要在这个空间里面进行计算比对就可以了。
3 为什么需要人脸对齐(face alignment)?人脸对齐可以消除姿态、角度等变化带来的影响,使网络更容易学习到判别性特征。姿态角度变化在人脸识别的过程中是一块难以解决的牛皮藓。
4 前面提到的人脸识别的一个方法-ArcFace,其实讲的是人脸特征提取模型训练时候用到的一个损失函数。至于什么是训练和损失函数,大家可以自行去了解了。
ArcFace
ArcFace是CVPR 2019上最先进的人脸识别方法。这是对ArcFace的最高评价。
InsightFace
核心思想
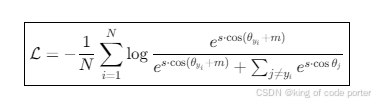
这是其数学公式,看起来头比较大,
其中:
- ( s ) 是特征缩放因子(通常设为64)
- ( m ) 是角度边界超参数(通常设为0.5弧度)
- ( ) 是特征与对应类别权重向量的夹角。
1. 角度空间映射
将人脸特征向量 和分类权重
进行L2归一化,映射到超球面空间,此时特征相似度由 余弦相似度 转换为 角度距离:
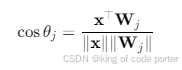
可以这么理解这个意思, 所有特征被压缩到半径为1的超球面,比较相似度时只依赖角度,不受向量长度影响(相当于把所有人脸特征投影到地球表面,距离用弧度衡量),经过L2归一化后,相当于统一了比较标准。
2. 角度边际增强
在目标类别的角度 上施加 加性角度边际 m,迫使同类样本在特征空间中更紧凑、异类样本更远离。这个是比较关键的创新,得到的效果就是类间特征紧凑,类外特征更远,有利于更好的进行区分。
3 缩放因子(放大差异)
将前面的余弦值乘以一个放大系数 s(通常s=64),相当于用放大镜看关键特征(缩放因子s),使得正确类的概率更加突出。
举个例子
例子背景设定
- 任务:训练模型将特征向量 x 正确分类到类别1(W₁)
- 当前状态:
- x 与 W₁ 的夹角 θ₁ = 40°
- x 与 W₂ 的夹角 θ₂ = 30°
- 参数设置:
- 角度边际 m = 20°
- 缩放因子 s = 2
第一步:传统Softmax的计算
1. 计算余弦相似度
- 对目标类(W₁):
cos40° ≈ 0.766 - 对非目标类(W₂):
cos30° ≈ 0.866
2. 计算Logits(未缩放)
- 直接输入Softmax:
Logits = [0.766, 0.866]
3. 计算概率
- 使用Softmax公式:
prob₁ = e^{0.766} / (e^{0.766} + e^{0.866}) ≈ 0.45prob₂ = 1 - 0.45 = 0.55 - 问题:模型认为x更可能属于类别2(概率55%),导致错误分类
第二步:ArcFace的计算
1. 对目标类施加角度边际
- 修改目标类的角度:
θ₁ + m = 40° + 20° = 60° - 计算新的余弦值:
cos60° = 0.5
2. 应用缩放因子
- 放大后的Logits:
Logits = [2*0.5, 2*0.866] = [1.0, 1.732]
3. 计算概率
- 使用Softmax:
prob₁ = e^{1.0} / (e^{1.0} + e^{1.732}) ≈ 0.27prob₂ = 1 - 0.27 = 0.73
第三步:为什么这会迫使模型调整?
关键机制:交叉熵损失函数
损失函数公式:
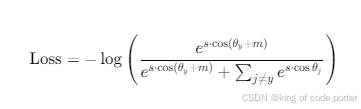
对比两种情况:
- 传统Softmax:正确类概率0.45 → 损失
-log(0.45) ≈ 0.8 - ArcFace:正确类概率0.27 → 损失
-log(0.27) ≈ 1.3
模型视角:
损失从0.8上升到1.3,意味着当前参数下分类效果变差。为了降低损失,模型必须调整参数,使得:
- x 与 W₁ 的夹角 θ₁ 减小(更靠近目标类中心)
- x 与 W₂ 的夹角 θ₂ 增大(远离非目标类)
第四步:模型如何调整?
假设经过训练后:
- x 与 W₁ 的夹角从40° → 20°
- x 与 W₂ 的夹角从30° → 50°
重新计算ArcFace:
- 目标类:
cos(20°+20°) = cos40° ≈ 0.766 - 非目标类:
cos50° ≈ 0.643 - Logits:
[2*0.766, 2*0.643] = [1.532, 1.286] - 概率:
prob₁ = e^{1.532}/(e^{1.532}+e^{1.286}) ≈ 0.56
此时损失 -log(0.56) ≈ 0.58,比原来的1.3显著降低。
这个例子似乎是有点道理,也能展示了前面的核心思想的作用。
ArcFace实现
import torchimport torch.nn as nnimport torch.nn.functional as Fclass ArcFace(nn.Module): def __init__(self, feat_dim, num_classes, s=64.0, m=0.5): super().__init__() self.s = s self.m = m self.W = nn.Parameter(torch.randn(feat_dim, num_classes)) def forward(self, features, labels): # 特征和权重归一化 features = F.normalize(features) W = F.normalize(self.W) # 计算余弦相似度 cos_theta = torch.mm(features, W) theta = torch.acos(torch.clamp(cos_theta, -1+1e-7, 1-1e-7)) # 添加角度边界 one_hot = torch.zeros_like(cos_theta) one_hot.scatter_(1, labels.view(-1,1), 1.0) cos_theta_m = torch.cos(theta + self.m * one_hot) # 缩放后计算损失 logits = self.s * (one_hot * cos_theta_m + (1-one_hot)*cos_theta) return F.cross_entropy(logits, labels)关键实现要点
1. 特征归一化 :对特征和权重矩阵都进行L2归一化,将相似度计算转化为纯角度比较
2. 角度计算 :使用arccos将余弦值转换为角度值
3. 边界添加 :仅在目标类别的角度上添加边界m
4. 特征缩放 :通过s参数控制特征在超球面上的分布紧密度
总结
这是一个从softmax变种过来的损失函数,ArcFace (Additive Angular Margin Loss) 通过 角度间隔惩罚 在超球面特征空间实现了:
- 类内特征最大紧凑性
- 类间特征最优区分度
- 几何解释性强且易于实现。
ArcFace已成为工业级人脸识别的黄金标准,在LFW(99.83%)、CFP-FP(98.02%)等基准上保持SOTA性能,其设计思想也被广泛应用于其他细粒度分类任务。
以上是有光ArcFace的一点个人见解,涉及到的公式和描述有不对的地方请指教,总的来说,人脸识别,数据才是王道。

