【机器学习-15】决策树(Decision Tree,DT)算法:原理与案例实现_决策算法
🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

前言
决策树算法是机器学习领域中的一种重要分类方法,它通过树状结构来进行决策分析。决策树凭借其直观易懂、易于解释的特点,在分类问题中得到了广泛的应用。本文将介绍决策树的基本原理,包括熵和信息熵的相关概念,以及几种经典的决策树算法。
在进行决策树的正式讲解之前,我们先来思考一个生活中常见的小问题。
问题:是否要和相亲对象见面?
思考过程:
(1)相亲对象的年纪?如果大于30岁月直接就不考虑了,如果小于等于30岁就继续思考下一个问题。
(2)相亲对象的长相?我们也是颜控,哈哈哈;如果长得丑就pass了,影响下一代,如果长相帅或中等就继续思考下一个问题。
(3)相亲对象的收入情况?将来的生活还是需要收入进行保障的,如果收入高的话就可以直接见面了,收入低的话就不考虑了见面了,收入中等话需要进一步可以他的工作。
(4)相亲对象是不是公务员?收入中等的人类,公务员可能拥有的时间比较多,将来可以更好的照顾家庭,所以是公务员的话就见面,不是公务员就不见面了。

一、决策树的定义
决策树是一种通过树形结构进行决策分析的分类方法。它采用一种自顶向下的递归方式,从根节点开始,在内部节点进行属性值的比较,并根据比较结果将样本分配到不同的子节点,直到达到叶节点,即最终的分类结果。决策树的每个节点表示一个对象,树枝代表可能的分类属性,而每个树叶则对应从根节点到该树叶所经历的路径所表示的对象的值。
二、熵和信息熵的相关概念
在决策树算法中,熵和信息熵的概念起到了至关重要的作用。它们帮助我们度量数据的混乱程度或不确定性,从而指导我们如何选择最优的划分属性。
2.1 信息熵的简单理解
信息熵是对数据集中不确定性或混乱程度的度量。在一个数据集中,如果各类别的样本数量大致相等,那么该数据集的熵值较高,表示不确定性较大;反之,如果某个类别的样本数量占据绝对优势,那么熵值较低,表示不确定性较小。因此,信息熵可以用来评估数据集的纯度。
设XXX是一个有限值的离散随机变量,其概率分布为:
P(X=xi)=pi,i=1,2,...,nP(X=x_i)=p_i,i=1,2,...,nP(X=xi)=pi,i=1,2,...,n
假设变量xxx的随机取值为X=x1,x2,...,xnX={x_1,x_2,...,x_n}X=x1,x2,...,xn,每一种取值的概率分布分别是p1,p2,pi{p_1,p_2,p_i}p1,p2,pi,则变量XXX的熵为:
H(X)=−∑i=1npilog2piH(X)=-\\sum_{i=1}^{n}p_ilog_{2}p_iH(X)=−i=1∑npilog2pi
案例解释:
假设我们有一个抛硬币的随机事件,其中正面朝上的概率为P(正面) = 0.5,反面朝上的概率为P(反面) = 0.5。那么,这个随机事件的信息熵为:
H(硬币)=−(0.5∗log2(0.5)+0.5∗log2(0.5))=−(0.5∗(−1)+0.5∗(−1))=1H(硬币) = - (0.5 * log2(0.5) + 0.5 * log2(0.5))= - (0.5 * (-1) + 0.5 * (-1))= 1H(硬币)=−(0.5∗log2(0.5)+0.5∗log2(0.5))=−(0.5∗(−1)+0.5∗(−1))=1
信息熵为1表示这个随机事件的不确定性为1,也就是说,我们无法确定硬币的哪一面会朝上,因为正面和反面的概率都是0.5。
2.2 条件熵
条件熵是在给定某个随机变量取值的情况下,另一个随机变量的不确定性度量。在决策树中,条件熵用于评估在给定某个特征条件下数据集的纯度。通过比较划分前后数据集的条件熵变化,我们可以选择出能够最大程度降低不确定性的划分属性。
数学公式:
条件熵(Conditional Entropy)表示在已知某一随机变量Y的条件下,另一随机变量X的不确定性。其公式为:
H(X∣Y)=ΣP(y)∗H(X∣y)=ΣP(y)∗[−ΣP(x∣y)∗log2P(x∣y)]H(X|Y) = Σ P(y) * H(X|y)= Σ P(y) * [- Σ P(x|y) * log_2P(x|y)]H(X∣Y)=ΣP(y)∗H(X∣y)=ΣP(y)∗[−ΣP(x∣y)∗log2P(x∣y)]
其中,P(y)P(y)P(y)表示随机变量YYY取值为yyy的概率,P(x∣y)P(x|y)P(x∣y)表示在YYY取值为yyy的条件下,XXX取值为xxx的条件概率。
案例解释:
假设我们有一个天气和穿衣的随机事件。其中,天气有两种状态:晴天和雨天,记为W = {晴, 雨};穿衣有三种选择:短袖、长袖和雨衣,记为C = {短袖, 长袖, 雨衣}。我们关心的是,在知道天气的情况下,穿衣选择的不确定性是多少。
首先,我们需要知道P(W=晴)、P(W=雨)、P(C=短袖|W=晴)、P(C=长袖|W=晴)、P(C=雨衣|W=晴)、P(C=短袖|W=雨)、P(C=长袖|W=雨)和P(C=雨衣|W=雨)。假设这些概率分别为:
P(W=晴) = 0.6, P(W=雨) = 0.4
P(C=短袖|W=晴) = 0.8, P(C=长袖|W=晴) = 0.1, P(C=雨衣|W=晴) = 0.1
P(C=短袖|W=雨) = 0.1, P(C=长袖|W=雨) = 0.2, P(C=雨衣|W=雨) = 0.7
然后,我们可以计算条件熵H(C|W)。这里需要分别计算晴天和雨天下的条件熵,然后按照天气的概率加权求和。
H(C|W=晴) = - (0.8 * log2(0.8) + 0.1 * log2(0.1) + 0.1 * log2(0.1))
H(C|W=雨) = - (0.1 * log2(0.1) + 0.2 * log2(0.2) + 0.7 * log2(0.7))
H(C|W) = 0.6 * H(C|W=晴) + 0.4 * H(C|W=雨)
条件熵H(C|W)表示在知道天气的条件下,穿衣选择的不确定性。这个值会比不考虑天气时的信息熵H©要小,因为天气信息为我们提供了关于穿衣选择的额外信息。
2.3 经典的决策树算法

根据划分标准的不同,决策树算法可以分为多种类型。其中,ID3、C4.5和CART是三种最为经典的决策树算法。
ID3算法采用信息增益作为划分标准,它选择信息增益最大的属性作为划分属性。然而,ID3算法倾向于选择取值较多的属性进行划分,可能导致过拟合问题。
C4.5算法是ID3算法的改进版,它采用信息增益率作为划分标准,克服了ID3算法中信息增益偏向选择取值较多的属性的缺点。此外,C4.5算法还增加了剪枝操作,进一步提高了模型的泛化能力。
CART算法则采用Gini系数作为划分标准,既可以用于分类问题也可以用于回归问题。CART算法生成的决策树是二叉树,每个非叶节点只有两个分支,因此更加简洁易懂。
- Hunt算法:最早的决策树算法是由Hunt等人于1966年提出,Hunt算法是许多决策树算法的基础,包括ID3、C4.5和CART等。
- ID3:1979年由澳大利亚的计算机科学家罗斯·昆兰所发表。其他科学家也根据ID3算法相继提出了ID4和ID5等算法。
- C4.5:考虑到ID4等名已被占用,昆兰只好将1993年更新的ID3算法命名为C4.5算法。
- CART:Classification and Regression Tree,可解决分类和回归问题。
三、ID3算法
ID3算法是决策树算法中的经典之一,它采用信息增益作为划分选择或划分标准。下面我们将详细介绍ID3算法的原理和实现步骤。
3.1 划分选择或划分标准——信息增益
信息增益是ID3算法中用于选择划分属性的标准。它表示划分前后数据集的信息熵的差值,差值越大说明划分效果越好。信息增益的计算基于经验熵(香农熵)的概念。
Gain(S,A)=E(S)−E(S,A)Gain(S,A)=E(S)-E(S,A)Gain(S,A)=E(S)−E(S,A)
如果:
Gian(S,A=‘相亲对象的年龄’)=E(S)-E(S,A=\'相亲对象的年龄’)=1-0.25=0.75
Gian(S,A=‘相亲对象长像’)=E(S)-E(S,A=\'相亲对象长像’)=1-0.41=0.59
因为0.75>0.59,所以选择\"相亲对象的年龄“作为样本集S的划分特征。接下来,递归调用算法。
下面将使用贷款申请样本的数据表来进行具体说明,数据示例如下:

在编写代码之前,先对数据集进行属性标注。
- 年龄:{“青年”:0, “中年”:1, “老年”:2}
- 有工作: {“否”:0, “是”:1}
- 有自己的房子: {“否”:0, “是”:1}
- 信贷情况: {“一般”:0, “好”:1, “非常好”:2}
- 类别(是否给贷款): {“否”:no, “是”:yes}
# 数据集dataSet=[[0, 0, 0, 0, \'no\'], [0, 0, 0, 1, \'no\'], [0, 1, 0, 1, \'yes\'], [0, 1, 1, 0, \'yes\'], [0, 0, 0, 0, \'no\'], [1, 0, 0, 0, \'no\'], [1, 0, 0, 1, \'no\'], [1, 1, 1, 1, \'yes\'], [1, 0, 1, 2, \'yes\'], [1, 0, 1, 2, \'yes\'], [2, 0, 1, 2, \'yes\'], [2, 0, 1, 1, \'yes\'], [2, 1, 0, 1, \'yes\'], [2, 1, 0, 2, \'yes\'], [2, 0, 0, 0, \'no\']]labels=[\'年龄\',\'有工作\',\'有自己的房子\',\'信贷情况\']3.2 计算经验熵(香农熵)
经验熵(香农熵)用于度量数据集的纯度或不确定性。对于包含K个类别的数据集DDD,其经验熵H(D)H(D)H(D)的计算公式如下:
H(D)=−Σ(P(Di)∗log2P(Di))H(D) = - Σ (P(D_i) * log2P(D_i))H(D)=−Σ(P(Di)∗log2P(Di))
其中,P(Di)表示数据集D中第i个类别样本所占的比例,Σ表示对所有类别求和。经验熵越小,说明数据集的纯度越高。
# 计算经验熵(香农熵)from math import logdef calcShannonEnt(dataSet): # 统计数据数量 numEntries = len(dataSet) # 存储每个label出现次数 label_counts = {} # 统计label出现次数 for featVec in dataSet: current_label = featVec[-1] if current_label not in label_counts: # 提取label信息 label_counts[current_label] = 0 # 如果label未在dict中则加入 label_counts[current_label] += 1 # label计数 shannon_ent = 0 # 经验熵 # 计算经验熵 for key in label_counts: prob = float(label_counts[key]) / numEntries shannon_ent -= prob * log(prob, 2) return shannon_entprint(\"输出结果为:\",calcShannonEnt(dataSet))3.3 计算信息增益
信息增益表示划分前后数据集信息熵的差值。对于属性AAA,其在数据集DDD上的信息增益Gain(D,A)Gain(D, A)Gain(D,A)的计算公式如下:
Gain(D,A)=H(D)−Σ(∣Dv∣/∣D∣∗H(Dv))Gain(D, A) = H(D) - Σ (|D_v|/|D| * H(D_v))Gain(D,A)=H(D)−Σ(∣Dv∣/∣D∣∗H(Dv))
其中,DvD_vDv表示根据属性AAA的某个取值将数据集DDD划分得到的子集,∣Dv∣|D_v|∣Dv∣表示子集DvD_vDv的样本数,∣D∣|D|∣D∣表示数据集DDD的样本总数。信息增益越大,说明使用属性A进行划分所获得的“纯度提升”越大。
def splitDataSet(data_set, axis, value): ret_dataset = [] for feat_vec in data_set: if feat_vec[axis] == value: reduced_feat_vec = feat_vec[:axis] reduced_feat_vec.extend(feat_vec[axis + 1:]) ret_dataset.append(reduced_feat_vec) return ret_datasetdef chooseBestFeatureToSplit(dataSet): # 特征数量 num_features = len(dataSet[0]) - 1 # 计算数据香农熵 base_entropy = calcShannonEnt(dataSet) # 信息增益 best_info_gain = 0.0 # 最优特征索引值 best_feature = -1 # 遍历所有特征 for i in range(num_features): # 获取dataset第i个特征 feat_list = [exampel[i] for exampel in dataSet] # 创建set集合,元素不可重合 unique_val = set(feat_list) # 经验条件熵 new_entropy = 0.0 # 计算信息增益 for value in unique_val: # sub_dataset划分后的子集 sub_dataset = splitDataSet(dataSet, i, value) # 计算子集的概率 prob = len(sub_dataset) / float(len(dataSet)) # 计算经验条件熵 new_entropy += prob * calcShannonEnt(sub_dataset) # 信息增益 info_gain = base_entropy - new_entropy # 打印每个特征的信息增益 print(\"第%d个特征的信息增益为%.3f\" % (i, info_gain)) # 计算信息增益 if info_gain > best_info_gain: # 更新信息增益 best_info_gain = info_gain # 记录信息增益最大的特征的索引值 best_feature = i print(\"最优索引值:\" + str(best_feature)) print() return best_featurechooseBestFeatureToSplit(dataSet)3.4 树的生成
ID3算法通过递归地选择信息增益最大的属性进行划分来生成决策树。具体步骤如下:
步骤1:从根节点开始,计算所有属性的信息增益。
步骤1:选择信息增益最大的属性作为划分属性,根据该属性的不同取值将数据集划分为多个子集。
步骤3:对每个子集递归执行步骤1和步骤2,直到满足停止条件(如所有样本属于同一类别或没有属性可用)为止。
通过上述步骤,我们可以得到一个完整的决策树。
import operatordef majority_cnt(class_list): class_count = {} # 统计class_list中每个元素出现的次数 for vote in class_list: if vote not in class_count: class_count[vote] = 0 class_count[vote] += 1 # 根据字典的值降序排列 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) return sorted_class_count[0][0]def creat_tree(dataSet, labels, featLabels): # 取分类标签(是否放贷:yes or no) class_list = [exampel[-1] for exampel in dataSet] # 如果类别完全相同则停止分类 if class_list.count(class_list[0]) == len(class_list): return class_list[0] # 遍历完所有特征时返回出现次数最多的类标签 if len(dataSet[0]) == 1: return majority_cnt(class_list) # 选择最优特征 best_feature = chooseBestFeatureToSplit(dataSet) # 最优特征的标签 best_feature_label = labels[best_feature] featLabels.append(best_feature_label) # 根据最优特征的标签生成树 my_tree = {best_feature_label: {}} # 删除已使用标签 del(labels[best_feature]) # 得到训练集中所有最优特征的属性值 feat_value = [exampel[best_feature] for exampel in dataSet] # 去掉重复属性值 unique_vls = set(feat_value) for value in unique_vls: my_tree[best_feature_label][value] = creat_tree(splitDataSet(dataSet, best_feature, value), labels, featLabels) return my_treecreat_tree(dataSet, labels, featLabels)3.5 树的深度和广度计算
决策树的深度和广度是评估树结构的重要指标。深度表示从根节点到最远叶节点的最长路径上的节点数;广度表示同一层上节点的数量。这些指标有助于我们了解树的复杂性和性能。
def get_num_leaves(my_tree): num_leaves = 0 first_str = next(iter(my_tree)) second_dict = my_tree[first_str] for key in second_dict.keys(): if type(second_dict[key]).__name__ == \'dict\': num_leaves += get_num_leaves(second_dict[key]) else: num_leaves += 1 return num_leavesdef get_tree_depth(my_tree): max_depth = 0 # 初始化决策树深度 firsr_str = next(iter(my_tree)) # python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] second_dict = my_tree[firsr_str] # 获取下一个字典 for key in second_dict.keys(): if type(second_dict[key]).__name__ == \'dict\': # 测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 this_depth = 1 + get_tree_depth(second_dict[key]) else: this_depth = 1 if this_depth > max_depth: max_depth = this_depth # 更新层数 return max_depthmy_tree = creat_tree(dataSet, labels, featLabels)print(\'树的深度为:\', get_tree_depth(my_tree))print(\'树的广度为:\', get_num_leaves(my_tree))3.6 未知数据的预测
对于未知数据,我们可以根据生成的决策树进行预测。从根节点开始,根据未知数据的属性值沿着树结构进行条件判断,最终到达叶节点得到预测结果。
def classify(input_tree, feat_labels, test_vec): # 获取决策树节点 first_str = next(iter(input_tree)) # 下一个字典 second_dict = input_tree[first_str] feat_index = feat_labels.index(first_str) for key in second_dict.keys(): if test_vec[feat_index] == key: if type(second_dict[key]).__name__ == \'dict\': class_label = classify(second_dict[key], feat_labels, test_vec) else: class_label = second_dict[key] return class_label# 测试testVec = [0, 1, 1, 1]my_tree = creat_tree(dataSet, labels, featLabels)result = classify(my_tree, featLabels, testVec)if result == \'yes\': print(\'放贷\')if result == \'no\': print(\'不放贷\')3.7 树的存储与读取(以二进制形式存储)
为了方便后续使用和管理,我们可以将生成的决策树以二进制形式存储到文件中。存储时,可以按照树的遍历顺序(如先序遍历)将节点的信息(如属性值、子节点指针等)编码为二进制数据并写入文件。读取时,按照相同的遍历顺序解码二进制数据并重建决策树。
import pickledef storeTree(input_tree, filename): # 存储树 with open(filename, \'wb\') as fw: pickle.dump(input_tree, fw)def grabTree(filename): # 读取树 fr = open(filename, \'rb\') return pickle.load(fr)3.8 完整代码
下面是一个简单的ID3算法实现示例(使用Python编写):
from math import logimport operatorimport pickledef calcShannonEnt(dataSet): # 统计数据数量 numEntries = len(dataSet) # 存储每个label出现次数 label_counts = {} # 统计label出现次数 for featVec in dataSet: current_label = featVec[-1] if current_label not in label_counts: # 提取label信息 label_counts[current_label] = 0 # 如果label未在dict中则加入 label_counts[current_label] += 1 # label计数 shannon_ent = 0 # 经验熵 # 计算经验熵 for key in label_counts: prob = float(label_counts[key]) / numEntries shannon_ent -= prob * log(prob, 2) return shannon_entdef splitDataSet(data_set, axis, value): ret_dataset = [] for feat_vec in data_set: if feat_vec[axis] == value: reduced_feat_vec = feat_vec[:axis] reduced_feat_vec.extend(feat_vec[axis + 1:]) ret_dataset.append(reduced_feat_vec) return ret_datasetdef chooseBestFeatureToSplit(dataSet): # 特征数量 num_features = len(dataSet[0]) - 1 # 计算数据香农熵 base_entropy = calcShannonEnt(dataSet) # 信息增益 best_info_gain = 0.0 # 最优特征索引值 best_feature = -1 # 遍历所有特征 for i in range(num_features): # 获取dataset第i个特征 feat_list = [exampel[i] for exampel in dataSet] # 创建set集合,元素不可重合 unique_val = set(feat_list) # 经验条件熵 new_entropy = 0.0 # 计算信息增益 for value in unique_val: # sub_dataset划分后的子集 sub_dataset = splitDataSet(dataSet, i, value) # 计算子集的概率 prob = len(sub_dataset) / float(len(dataSet)) # 计算经验条件熵 new_entropy += prob * calcShannonEnt(sub_dataset) # 信息增益 info_gain = base_entropy - new_entropy # 打印每个特征的信息增益 print(\"第%d个特征的信息增益为%.3f\" % (i, info_gain)) # 计算信息增益 if info_gain > best_info_gain: # 更新信息增益 best_info_gain = info_gain # 记录信息增益最大的特征的索引值 best_feature = i print(\"最优索引值:\" + str(best_feature)) print() return best_featuredef majority_cnt(class_list): class_count = {} # 统计class_list中每个元素出现的次数 for vote in class_list: if vote not in class_count: class_count[vote] = 0 class_count[vote] += 1 # 根据字典的值降序排列 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) return sorted_class_count[0][0]def creat_tree(dataSet, labels, featLabels): # 取分类标签(是否放贷:yes or no) class_list = [exampel[-1] for exampel in dataSet] # 如果类别完全相同则停止分类 if class_list.count(class_list[0]) == len(class_list): return class_list[0] # 遍历完所有特征时返回出现次数最多的类标签 if len(dataSet[0]) == 1: return majority_cnt(class_list) # 选择最优特征 best_feature = chooseBestFeatureToSplit(dataSet) # 最优特征的标签 best_feature_label = labels[best_feature] featLabels.append(best_feature_label) # 根据最优特征的标签生成树 my_tree = {best_feature_label: {}} # 删除已使用标签 del(labels[best_feature]) # 得到训练集中所有最优特征的属性值 feat_value = [exampel[best_feature] for exampel in dataSet] # 去掉重复属性值 unique_vls = set(feat_value) for value in unique_vls: my_tree[best_feature_label][value] = creat_tree(splitDataSet(dataSet, best_feature, value), labels, featLabels) return my_treedef get_num_leaves(my_tree): num_leaves = 0 first_str = next(iter(my_tree)) second_dict = my_tree[first_str] for key in second_dict.keys(): if type(second_dict[key]).__name__ == \'dict\': num_leaves += get_num_leaves(second_dict[key]) else: num_leaves += 1 return num_leavesdef get_tree_depth(my_tree): max_depth = 0 # 初始化决策树深度 firsr_str = next(iter(my_tree)) # python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] second_dict = my_tree[firsr_str] # 获取下一个字典 for key in second_dict.keys(): if type(second_dict[key]).__name__ == \'dict\': # 测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 this_depth = 1 + get_tree_depth(second_dict[key]) else: this_depth = 1 if this_depth > max_depth: max_depth = this_depth # 更新层数 return max_depthdef classify(input_tree, feat_labels, test_vec): # 获取决策树节点 first_str = next(iter(input_tree)) # 下一个字典 second_dict = input_tree[first_str] feat_index = feat_labels.index(first_str) for key in second_dict.keys(): if test_vec[feat_index] == key: if type(second_dict[key]).__name__ == \'dict\': class_label = classify(second_dict[key], feat_labels, test_vec) else: class_label = second_dict[key] return class_labeldef storeTree(input_tree, filename): # 存储树 with open(filename, \'wb\') as fw: pickle.dump(input_tree, fw)def grabTree(filename): # 读取树 fr = open(filename, \'rb\') return pickle.load(fr)if __name__ == \"__main__\": # 数据集 dataSet = [[0, 0, 0, 0, \'no\'], [0, 0, 0, 1, \'no\'], [0, 1, 0, 1, \'yes\'], [0, 1, 1, 0, \'yes\'], [0, 0, 0, 0, \'no\'], [1, 0, 0, 0, \'no\'], # [1, 0, 0, 0, \'yes\'], [1, 0, 0, 1, \'no\'], [1, 1, 1, 1, \'yes\'], [1, 0, 1, 2, \'yes\'], [1, 0, 1, 2, \'yes\'], [2, 0, 1, 2, \'yes\'], [2, 0, 1, 1, \'yes\'], [2, 1, 0, 1, \'yes\'], [2, 1, 0, 2, \'yes\'], [2, 0, 0, 0, \'no\']] # 分类属性 labels = [\'年龄\', \'有工作\', \'有自己的房子\', \'信贷情况\'] print(dataSet) print() print(calcShannonEnt(dataSet)) print() featLabels = [] myTree = creat_tree(dataSet, labels, featLabels) print(myTree) print(get_tree_depth(myTree)) print(get_num_leaves(myTree)) #测试数据 testVec = [0, 1, 1, 1] result = classify(myTree, featLabels, testVec) if result == \'yes\': print(\'放贷\') if result == \'no\': print(\'不放贷\') # 存储树 storeTree(myTree,\'classifierStorage.txt\') # 读取树 myTree2 = grabTree(\'classifierStorage.txt\') print(myTree2) testVec2 = [1, 0] result2 = classify(myTree2, featLabels, testVec) if result2 == \'yes\': print(\'放贷\') if result2 == \'no\': print(\'不放贷\')3.9 ID3算法的优缺点
ID3算法的优点在于原理简单易懂,生成的决策树易于理解。然而,它也存在一些缺点:
1、ID3算法只能处理离散型属性,对于连续型属性需要进行额外的处理。
2、ID3算法在划分属性时偏向于选择取值较多的属性,这可能导 致生成的决策树过于复杂,出现过拟合现象。
3、ID3算法没有考虑剪枝操作,生成的决策树可能存在冗余分支,影响预测性能。
为了克服这些缺点,后续的研究者提出了C4.5算法等改进版本,通过引入对连续型属性的处理、使用信息增益率代替信息增益作为划分标准以及引入剪枝操作等方式来优化决策树的生成过程。
四、C4.5算法
C4.5算法是ID3算法的改进版,它解决了ID3算法的一些局限性,如偏向于选择取值较多的属性、不能处理连续型属性以及未考虑剪枝操作等问题。下面我们将详细介绍C4.5算法中的信息增益率、剪枝操作以及ID3和C4.5的结果比较。
4.1 信息增益率
C4.5算法采用信息增益率作为划分选择或划分标准,以克服ID3算法偏向于选择取值较多的属性的问题。定义:设有限个样本集合SSS,根据条件属性AAA划分SSS所得子集为S1,S2,...,Sn{S_1,S_2,...,S_n}S1,S2,...,Sn,则定义AAA划分样本集SSS的信息增益率为:
GainRate(S,A)=Gain(S,A)/IV(A)GainRate(S,A)=Gain(S,A)/IV(A)GainRate(S,A)=Gain(S,A)/IV(A)
其中,Gain(S,A)的计算公式为Gain(S,A)=E(S)-E(S,A),IV(A)如下:
IV(A)=−∑j=1v∣Sj∣∣S∣log2(∣Sj∣∣S∣)IV(A)=-\\sum_{j=1}^{v}\\frac{|S_j|}{|S|}log_2(\\frac{|S_j|}{|S|})IV(A)=−j=1∑v∣S∣∣Sj∣log2(∣S∣∣Sj∣)
称为属性A的“固有值”,属性A的取值数目越多,即v越大,则IV(A)的值通常会越大。通过引入固有值的概念,信息增益率能够平衡属性取值多样性和信息增益之间的关系,从而选择出更具代表性的划分属性。
4.2 C4.5的剪枝
C4.5算法引入了剪枝操作来避免决策树过拟合。剪枝操作分为预剪枝和后剪枝两种。
预剪枝是在决策树生成过程中提前停止树的生长,通过设定一些停止条件(如节点中样本数少于某个阈值、信息增益小于某个阈值等)来限制树的深度。这种方法简单有效,但可能由于过早停止树的生长而导致欠拟合。
后剪枝是在决策树生成完成后对其进行修剪,通过删除一些子树或叶子节点来简化树的结构。C4.5算法采用了一种基于错误率降低的剪枝策略,通过计算删除某个子树前后的错误率变化来决定是否进行剪枝。这种方法能够保留更多的有用信息,但计算复杂度较高。
通过剪枝操作,C4.5算法能够在保证一定性能的前提下简化决策树的结构,提高模型的泛化能力。
4.3 ID3和C4.5的结果比较
ID3和C4.5算法在决策树生成过程中有着明显的不同。ID3算法采用信息增益作为划分标准,容易偏向于选择取值较多的属性,可能导致生成的决策树过于复杂。而C4.5算法通过引入信息增益率和剪枝操作,有效克服了这些问题,能够生成更加简洁、有效的决策树。
在实际应用中,C4.5算法通常能够取得比ID3算法更好的性能。它不仅能够处理离散型属性,还能通过离散化处理来应对连续型属性。此外,C4.5算法的剪枝操作能够有效防止过拟合,提高模型的泛化能力。因此,在需要构建决策树模型时,C4.5算法通常是一个更好的选择。
需要注意的是,虽然C4.5算法在很多方面都有所改进,但它仍然是一种基于启发式规则的算法,其性能受到数据集特性的影响。在实际应用中,我们需要根据具体问题和数据集特点来选择合适的算法和参数设置。
五、CART算法
CART(Classification and Regression Trees)(分类回归树)分为分类树和回归树算法是一种应用广泛的决策树学习算法,既可以用于分类也可以用于回归。需要特别说明的是sklearn中的决策树算法 DecisionTreeRegressor、DecisionTreeClassifier 使用的都是CART算法。下面我们将详细介绍CART算法的原理、划分标准、优缺点以及实际案例实现。
5.1 CART树
CART树是一种二叉树,这意味着每个非叶子节点都有两个子节点。对于分类问题,CART树采用二分类的方式,每次将数据划分为两个子集;对于回归问题,CART树则是将输出值划分为连续型的值。
分类树和ID3、C45决策树相似,都是用来处理分类问题,不同之处是划分方式不同,CART分类树利用基尼指数进行二分,如下所示就是一个分类树:
回归树用来处理回归问题,回归将已知数据进行拟合,对于目标变量未知的数据可以预测目标变量的值,回归树中的损失函数是用于衡量预测值与真实值之间的误差的函数。在回归树中,最常见的损失函数是平方误差损失函数。平方误差损失函数计算预测值与真实值之间的差的平方,并将其累加以得到总体损失。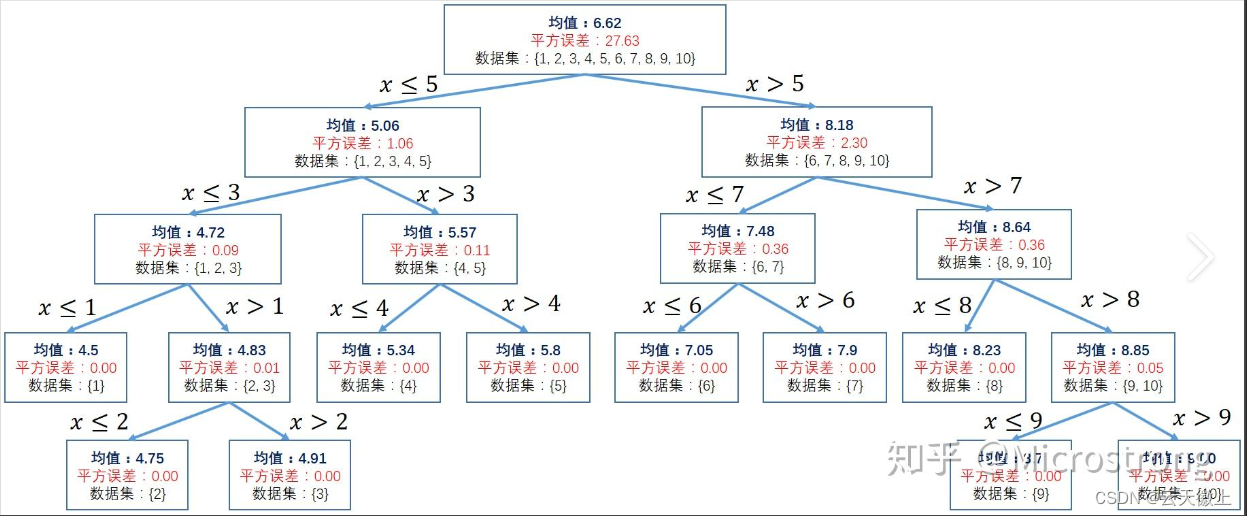
5.2 分类树划分选择——Gini系数
在分类问题中,CART树使用Gini系数作为划分选择或划分标准。Gini系数表示样本集合的不确定性,其值越小表示集合的纯度越高。对于含有K个类别的样本集合D,其Gini系数的计算公式为:
Gini(S)=∑i=1kpi(1−pi)=1−∑i=1k(pi)2Gini(S)=\\sum_{i=1}^kp_i(1-p_i)=1-\\sum_{i=1}^{k}(p_i)^2Gini(S)=i=1∑kpi(1−pi)=1−i=1∑k(pi)2
当对一个属性进行划分时,我们希望划分后的子集的Gini系数之和最小,即不确定性最小。
假设我们有一个包含10个样本的集合,其中5个属于类别A,3个属于类别B,2个属于类别C。那么该集合的Gini系数为:
Gini(D)=1−(5/10)2−(3/10)2−(2/10)2=0.48Gini(D) = 1 - (5/10)^2 - (3/10)^2 - (2/10)^2 = 0.48Gini(D)=1−(5/10)2−(3/10)2−(2/10)2=0.48
如果我们根据某个属性将集合划分为两个子集D1D1D1和D2D2D2,那么划分后的Gini系数之和为:
Ginisplit=(N1/N)∗Gini(D1)+(N2/N)∗Gini(D2)Gini_{split} = (N1/N) * Gini(D1) + (N2/N) * Gini(D2)Ginisplit=(N1/N)∗Gini(D1)+(N2/N)∗Gini(D2)
其中,N1N1N1和N24N24N24分别是子集D1D1D1和D2D2D2的样本数,NNN是总样本数。我们需要找到使GinisplitGini_{split}Ginisplit最小的划分方式。
5.3 回归树划分选择——loss函数
CART回归树预测回归连续型数据,假设X与Y分别示输入和输出变量,并且Y是连续变量,在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树。
D=(x1,y1),(x2,y2),...,(xn,yn)D={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}D=(x1,y1),(x2,y2),...,(xn,yn)
既然是回归树,那么必然会存在以下两个核心问题:
- 如何选择划分点?
- 如何决定树中叶节点的输出值?
选择最优切分变量j与切分点sss:便历变量jjj,对规定的切分变量jjj扫描切分点sss,选择使下式得到最小值时的(0j,s)(0j,s)(0j,s)对,其中RmR_mRm是被划分的输入空间,cmc_mcm是空间RmR_mRm对应的固定值;
用选定的(j,s)(j,s)(j,s)对,划分区域并决定相应的输出值:
R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>sR_1(j,s)={x|x^{(j)} \\leq s},R_2(j,s)={x|x^{(j)} > s}R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>s
c^m=1Nm∑xi∈Rm(j,s)yi,x∈Rm,m=1,2\\hat{c}_{m}=\\frac{1}{N_m}\\sum_{x_i \\in R_m(j,s)}y_i,x \\in R_m, m=1,2c^m=Nm1xi∈Rm(j,s)∑yi,x∈Rm,m=1,2
继续对两个子区域调用上述步骤,将输入空间划分为MMM个区域R1,R2,...,RmR_1,R_2,...,R_mR1,R2,...,Rm,生成决策树。
f(x)=∑m=1Ma^mI(x∈Rm)f(x) = \\sum_{m=1}^{M}\\hat{a}_{m}I(x \\in R_m)f(x)=m=1∑Ma^mI(x∈Rm)
当输入空间划分确定时,可以用平方误差来表示回归树对于训练数据的预测方法,用平方误差最小的准则求解每个单元上的最优输出值。
f(x)=∑x∈Rm(yi−f(xi))2f(x) = \\sum_{x\\in R_m}(y_i-f(x_i))^2f(x)=x∈Rm∑(yi−f(xi))2
对于回归问题,CART算法采用平方误差作为划分标准。对于每个划分点,计算划分后两个子集的平方误差之和,并选择使误差之和最小的划分点进行划分。最终生成的决策树可以用于对新数据进行回归预测。
5.4 CART算法的优缺点
优点:
- 既可以用于分类也可以用于回归,具有广泛的应用场景。
- 能够生成易于理解的决策树,方便进行特征解释和可视化。
- 对缺失值不敏感,能够处理包含缺失值的数据集。
缺点:
- 容易过拟合,特别是在没有剪枝的情况下。
- 对噪声数据较为敏感,可能生成复杂的决策树。
- 在某些情况下可能不如其他算法(如随机森林、梯度提升树等)表现优秀。
- CART树是根据Gini系数来衡量结点的不纯度,选择产生最小Gini系数的特征作为划分属性。
5.5 其他比较
与ID3和C4.5算法相比,CART算法采用了二叉树结构和Gini系数作为划分标准,使得决策树更加简洁和高效。同时,CART算法还支持回归问题,具有更广泛的应用范围。
-
划分标准的差异:ID3使用信息增益偏向特征值多的特征;C4.5使用信息增益率克服信息增益的缺点,偏向于特征值小的特征;CART使用基尼指数克服C4.5需要求log的巨大计算量,偏向于特征值较多的特征。
-
使用场景的差异:ID3和C4.5都只能用于分类问题,CART可以用于分类和回归问题;ID3和C4.5是多叉树,速度较慢,CART是二叉树,计算速度很快;
-
样本数据的差异:ID3只能处理离散数据且缺失值敏感,C4.5和CART可以处理连续性数据且有多种方式处理缺失值;从样本量考虑的话,小样本建议C4.5、大样本建议CART。C4.5处理过程中需对数据集进行多次扫描排序,处理成本耗时较高,而CART本身是一种大样本的统计方法,小样本处理下泛化误差较大;
-
样本特征的差异:ID3和C4.5层级之间只使用一次特征,CART可多次重复使用特征;
-
剪枝策略的差异:ID3没有剪枝策略,C4.5是通过悲观剪枝策略来修正树的准确性,而 CART是通过代价复杂度剪枝。
5.6 连续值的处理
对于连续型属性,CART算法采用二分法进行处理。具体做法是对连续属性进行排序,考虑相邻属性值的平均值作为划分点,然后选择使划分后子集Gini系数之和最小的划分点进行划分。
六、Python实现分类案例及可视化
下面我们将使用Python的scikit-learn库来实现决策树算法,并通过一个简单的案例来展示其应用过程。
首先,我们需要导入必要的库和数据集。这里我们使用scikit-learn自带的鸢尾花(Iris)数据集作为示例。
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)接下来,我们创建决策树分类器对象,并使用训练数据对其进行训练。# 创建决策树分类器对象 clf = DecisionTreeClassifier() # 使用训练数据对分类器进行训练 clf.fit(X_train, y_train)训练完成后,我们可以使用测试数据对模型进行评估,并计算分类准确率。# 使用测试数据进行预测 y_pred = clf.predict(X_test) # 计算分类准确率 accuracy = accuracy_score(y_test, y_pred) print(\"Accuracy:\", accuracy)测试集的准确率:Accuracy: 1.0通过以上代码,我们成功地使用决策树算法对鸢尾花数据集进行了分类,并计算了模型的分类准确率。当然,这只是一个简单的示例,实际应用中可能需要对数据进行预处理、特征选择等操作,以提高模型的性能。
上述我们使用clf=DecisionTreeClassifier()函数的时候设置参数max_depth=1,其实DecisionTreeClassifier是一个用于构建决策树模型的Python库。以下是该函数的参数解释:
-
criterion(标准化度量):指定使用哪种标准化度量方法,可选值包括“entropy”(信息熵)和“gini”(基尼系数)。默认值为“entropy”。
-
min_samples_leaf(叶子节点最小样本数):如果一个叶子节点的样本数小于这个值,则将其视为噪声点,并在训练集中删除。默认值为3。
-
max_depth(最大深度):指定决策树中的最大深度。深度越大,越容易过拟合,推荐树的深度为5-20之间。默认值为None。
-
random_state(随机种子):用于生成均匀分布的随机数。如果不提供,则会使用当前时间作为随机种子。默认值为None。
如果我们将上述函数的参数设置为2,即clf=DecisionTreeClassifier(max_depth=2),那么预测的精度就会发生改变,这是由于树的深度越大,越容易发生过拟合。也就是我们上面所说的,下面我们看下设置为参数设置为2的时候的精度变化。
好奇:决策树在每一层都做了哪些事情?
为了更好地理解和分析决策树模型,我们可以使用可视化工具将其呈现出来。在Python中,我们可以使用matplotlib和scikit-learn的tree模块来实现决策树的可视化。
下面是一个简单的示例代码:
import matplotlib.pyplot as plt from sklearn import tree # 绘制决策树 fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=800) tree.plot_tree(clf, feature_names = iris.feature_names, class_names=iris.target_names, filled = True,fontsize=10) plt.show()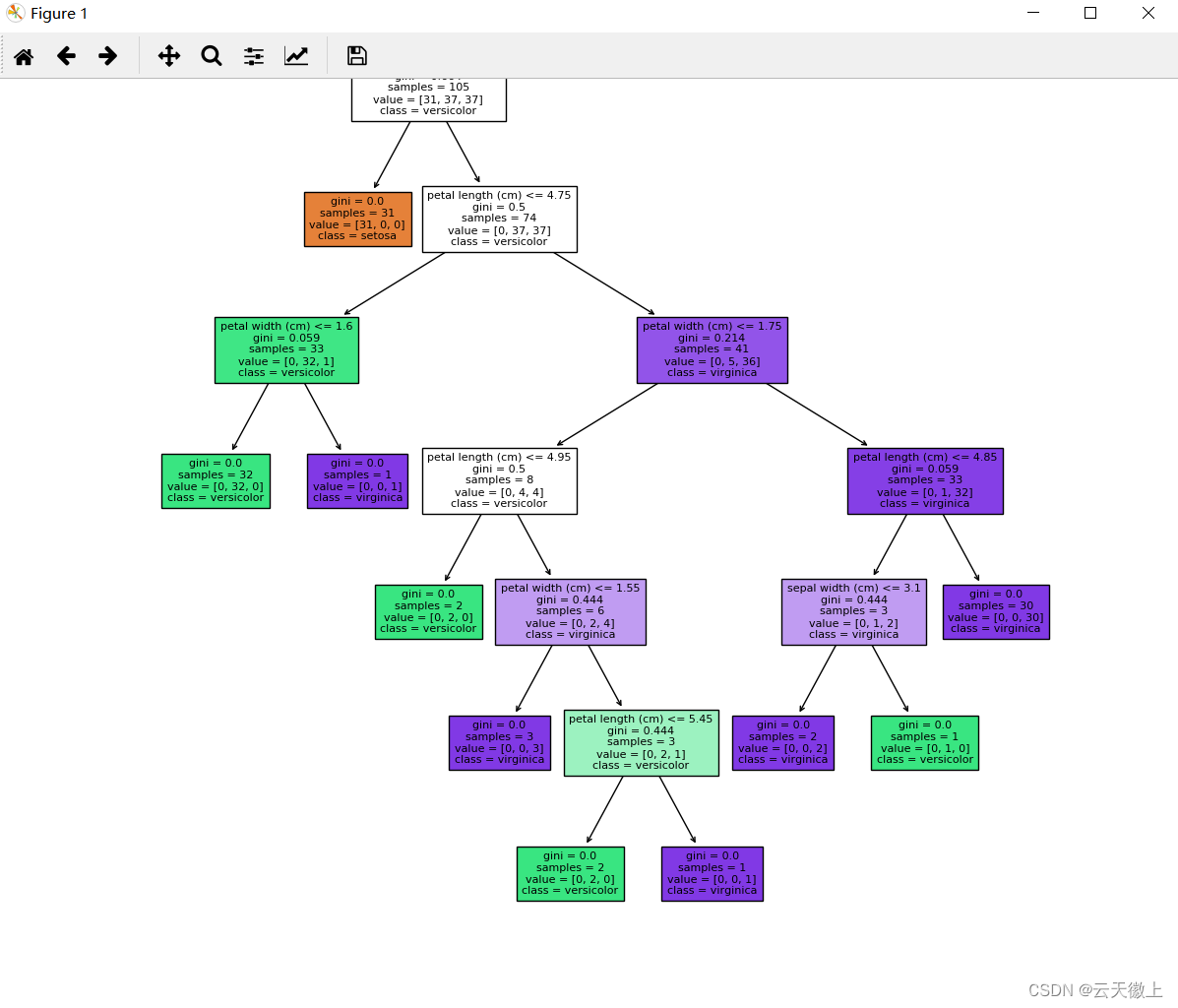
上述代码将生成一个决策树的图形表示,其中每个节点表示一个属性判断条件,每个分支表示一个取值情况,叶子节点表示最终的类别或回归值。通过可视化工具,我们可以直观地看到决策树的结构和决策过程,从而更好地理解模型的工作原理。
注:这里可能会出现图片显示不全的情况,需要设置fontsize=10参数和plt.figure(figsize=(20,20)画布大小来显示全部图片。
七、Python实现回归案例及可视化
下面我们将使用Python的scikit-learn库来实现决策树回归算法,并通过一个简单的案例来展示其应用过程。
首先,我们需要导入必要的库和数据集。这里我们使用scikit-learn自带的波士顿房价数据集作为示例。
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_squared_error import matplotlib.pyplot as plt # 加载波士顿房价数据集 boston = load_boston() X = boston.data y = boston.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)接下来,我们创建决策树回归器对象,并使用训练数据对其进行训练。# 创建决策树回归器对象 regressor = DecisionTreeRegressor(random_state=42) # 使用训练数据对回归器进行训练 regressor.fit(X_train, y_train)训练完成后,我们可以使用测试数据对模型进行评估,并计算均方误差(MSE)。# 使用测试数据进行预测 y_pred = regressor.predict(X_test) # 计算均方误差 mse = mean_squared_error(y_test, y_pred) print(\"Mean Squared Error:\", mse)运行结果Mean Squared Error: 11.588026315789474通过以上代码,我们成功地使用决策树回归算法对波士顿房价数据集进行了预测,并计算了模型的均方误差。
对于决策树回归模型的可视化,我们可以使用plot_tree函数来绘制决策树的结构。与分类决策树的可视化类似,但需要注意的是,回归树的叶子节点输出的是具体的数值。
from sklearn import tree # 绘制决策树回归模型 fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(10, 10), dpi=800) tree.plot_tree(regressor, feature_names=boston.feature_names, filled=True, rounded=True, special_characters=True) plt.show()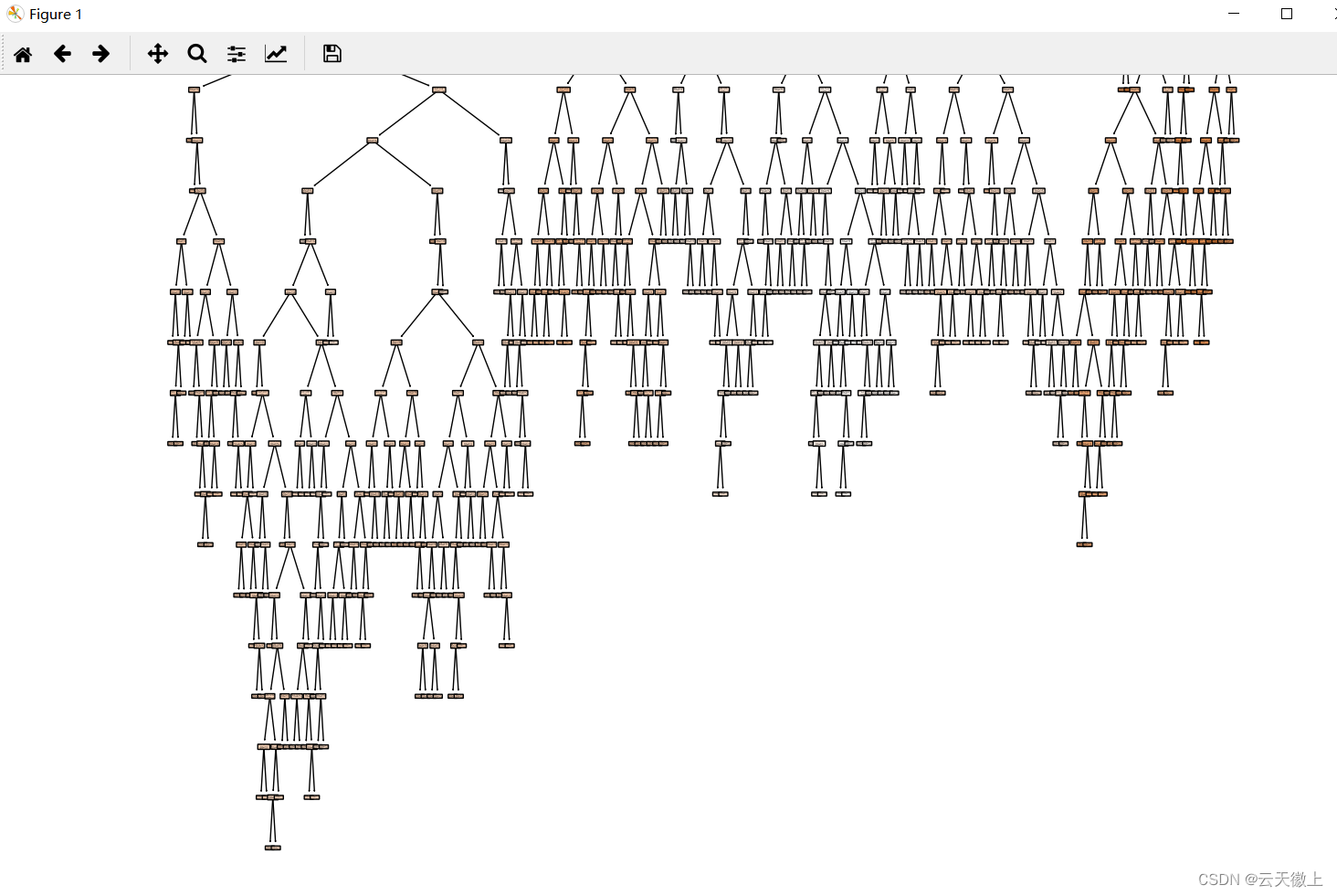
看不出来什么结果,后续将会写一个文章说明这个绘图显示的问题;
这段代码将生成一个决策树回归模型的图形表示。你可以通过图形直观地看到每个节点上的划分条件以及叶子节点上的预测值。这对于理解模型的工作方式和解释预测结果非常有帮助。
八、总结
本文介绍了决策树算法的原理和Python实现案例,并通过可视化方法展示了决策树模型的结构和决策过程。决策树算法具有直观易懂、易于解释的优点,在分类和回归问题中都有广泛的应用。通过学习和实践决策树算法,我们可以更好地理解机器学习的基本原理和应用方法,为后续的机器学习研究和应用打下坚实的基础。


