Mysql实现高可用(主从、集群)
一、背景
需求:客户要实现Mysql8.0+高可用,出现故障时,需要实现自动切换。
分析:实现切换有两种方式,一种数据库自动切换,一种代码实现。
本着麻烦别人,别麻烦自己的原则,得给客户的DBA派活儿了。
实现MySQL数据库集群自动切换,核心目标是高可用性(High Availability, HA),即在主节点故障时,系统能自动、快速、安全地将服务切换到备用节点,最大限度减少停机时间。

二、方案收集
2.1. 方案一:主从复制
基于主从复制 + 高可用中间件/工具 (最主流、灵活) 架构: 1 个主节点( Master ) : 负责处理所有读写请求。 1 个或多个从节点( Slave ) : 通过 MySQL 原⽣异步 /半同步复制从主节点同步数据,通常配置为只读。 ⾼可⽤管理器 : Keepalived + VRRP: 提供⼀个虚拟 IP ( VIP )。Keepalived监控主节点健康状态,若主故障,通过 VRRP 协议将 VIP漂移到选定的从节点(需配合脚本提升该从为主)。 MHA (Master High Availability): 专为 MySQL设计的成熟⼯具。Manager节点监控所有节点,主故障时⾃动选择最新数据的从节点,将其提升为新主,并尝试让其他从库指向新主。⽀持故障转移、主节点切换等。 (不维护啦,不做推荐) ProxySQL / MaxScale (MariaDB) / HAProxy: 智能代理 层。应⽤连接代理,代理将写请求转发给主节点,读请求 可转发给从节点。代理持续监控后端节点健康状态。主节 点故障时,代理⾃动将写流量切换到新的主节点(通常需要配合 pt-heartbeat 或代理内置机制检测延迟和复制状态)。 【⾃动切换流程:】 1. 监控组件持续检测主节点健康(⽹络可达性、 MySQL进程状 态、复制状态、⾃定义脚本如 SELECT 1 )。 2. 检测到主节点故障(超时⽆响应、服务宕机、复制严重延迟 等)。 3. ⾼可⽤管理器触发故障转移流程: 确认主节点确实不可⽤(防⽌误判)。 选择⼀个最合适的从节点(通常是数据最接近主节点、复 制延迟最⼩的那个)。 提升该从节点为新的主节点(执⾏ STOP SLAVE; RESETSLAVE ALL; 或类似操作,确保其可写)。 如果使⽤ VIP ,则让 VIP 漂移到新主节点。 如果使⽤代理,则更新代理配置,将写请求指向新主。 (可选)让其他从节点开始从新主节点复制数据。 4. 应⽤通过 VIP 或代理重新连接到新的主节点,恢复服务。 【优点】 技术成熟、灵活(可⾃由选择组件)、成本相对较低(开源软件为主)、⽀持读写分离。 缺点: 配置和管理相对复杂;异步复制存在数据丢失⻛险(除⾮⽤半同步);脑裂⻛险需妥善处理(如使⽤第三⽅仲裁);代理层本⾝需要⾼可⽤(可⽤双活代理 +Keepalived VIP )。 适⽤场景 : 对成本敏感、需要灵活配置、可接受⼀定配置复杂度的场景。是当前最⼴泛采⽤的⽅案。
2.2. 方案二:MGR
MySQL Group Replication (MGR) - MySQL官⽅⽅案
架构: ⾄少3个节点(推荐单主模式)
基于Paxos分布式⼀致性协议实现数据同步(多数派确认)。
内置组成员管理、故障检测和⾃动主节点选举。 单主模式:只有⼀个节点可写(主节点),其他节点只读(但具备完整数据)。 多主模式:所有节点均可读写(但冲突检测和性能开销⼤,⽣产环境慎⽤)。 【⾃动切换流程:】 1. 组内节点通过组通信系统持续通信。 2. 如果主节点故障或⽹络分区导致失联。 3. 剩余存活节点(需构成多数派)会⾃动检测到主节点缺失。 4. 组内⾃动发起选举,根据预设规则(如 group_replication_member_weight )从存活的、数据⼀致的节 点中选出新的主节点。 5. 选举过程快速(通常秒级)。⼀旦新主当选,组内状态更新。 6. 应⽤需要感知新的主节点地址(通常需配合连接器如MySQL Router )。 【优点】 原⽣集成于MySQL ( >=5.7.17),⽆需额外中间件(除Router外);内置强⼀致性保证(⾏级冲突检测);⾃动故障检测与选举; 避免脑裂(需多数派存活);⽀持多节点写⼊(多主模式)。 【缺点】 性能开销⽐异步复制⼤(需要多数派确认写操作);对⽹络延 迟和稳定性要求极⾼;配置和管理有特定要求;脑裂后恢复可能复 杂;单主模式下读扩展性不如主从+ 代理。 【适⽤场景】 对强⼀致性要求⾼、愿意接受⼀定性能开销、希望使⽤官 ⽅原⽣⽅案、⽹络环境良好的场景。是未来发展的重点⽅向。 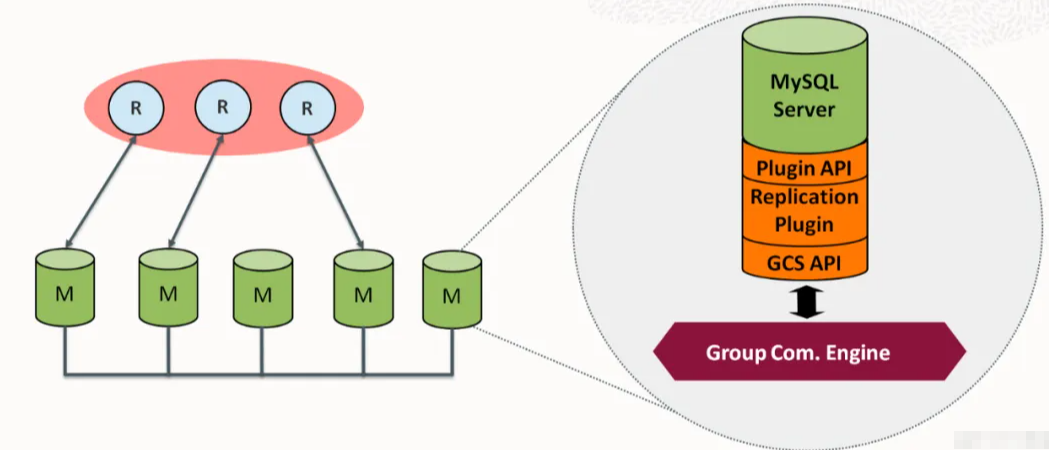
2.3. 方案三:PXC/Galera Cluster
Percona XtraDB Cluster (PXC) / Galera Cluster 架构:
- ⾄少3个节点。
- 基于Galera库实现的同步多主集群。
- 所有节点均可读写,数据写⼊在提交前必须在集群内同步到其
- 他节点(通过Certification-Based Replication)。
- 使⽤基于组通信的 gcomm 协议进⾏节点间通信。
【⾃动切换流程:】 严格来说, PXC/Galera 没有传统意义上的 “ 主从切换 ”,因为它 是多主的。 如果某个节点故障,只要集群多数派( Quorum)存活(通常 N/2+1 ),集群就能继续提供服务(读写在存活节点上进⾏)。 故障节点恢复后会从 Donor 节点⾃动进⾏ SST (State Snapshot Transfer )或 IST ( Incremental State Transfer)同步数据重新加 ⼊集群。 【优点】 真正的多主读写;强⼀致性;⾼可⽤性(节点故障对服务影响⼩,只要满⾜Quorum);⾃动成员管理和故障恢复;数据⼏乎⽆丢 失⻛险。 【缺点】 写性能受限于最慢节点和⽹络(同步复制开销);写冲突可能导致回滚;需要较⼤的 wsrep_slave_threads ; SST过程可能影响Donor 性能;对⽹络要求极⾼; DDL 操作需要特别⼩⼼。 【适⽤场景】 需要真正的多主写⼊、对强⼀致性和⾼可⽤性要求极⾼、 能接受同步复制带来的潜在性能瓶颈的场景。 2.4. 方案四:云数据库 云数据库⾼可⽤服务 ( 省⼼之选 ) 架构 : 直接使⽤阿⾥云 RDS 、 AWS RDS 、Azure Database for MySQL 、腾讯云 CDB 等提供的托管 MySQL 服务。 云厂商在其底层实现了⾼可⽤⽅案(通常是主从复制 +类似Keepalived/MHA的⾃动故障转移,或基于共享存储如阿⾥云三节点企业版) 【⾃动切换流程:】 完全由云平台管理。主节点故障时,云平台⾃动检测并触发故障转移,提升备节点为主节点。 切换过程对应⽤透明(通常通过 DNS 或 Endpoint ⾃动重定向)。 优点: 开箱即⽤,运维复杂度极低;云⼚商负责底层维护、监控、备份等;通常有 SLA 保障。 【缺点】 成本通常⾼于⾃建;灵活性受限于云平台提供的功能和配置选项; 可能存在⼚商锁定⻛险。 【适⽤场景】 希望最⼤程度减少数据库运维负担、预算充⾜、对云平台 信任的场景。
三、决策
3.1方案比较
到底应该使用哪种方案呢? 云方案首先排除,客户是自建服务。 那就对比方案一和方案二: 【提问】通过MySQL原生异步/半同步复制从主节点同步数据。和MGR方案的同步有什么区别呢? 【分析】
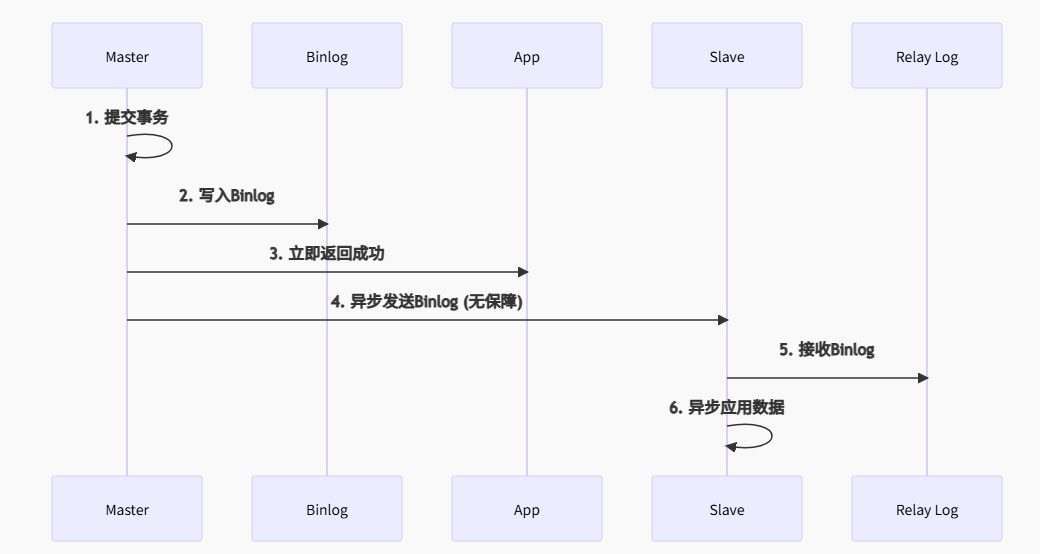
3.1.1 原生异步复制 (Async Replication)
特点:
- 数据可能丢失:Master 提交后即返回,Binlog 未同步到 Slave
- 延迟无上限:Slave 可能落后 Master 数小时
3.1.2 半同步复制 (Semi-Sync)
特点:
防丢数据:确保事务 Binlog 到达至少一个 Slave
不防延迟:Slave 可能未应用日志(仅保证收到)
主宕机仍丢数据:若 ACK 后 Slave 未应用日志
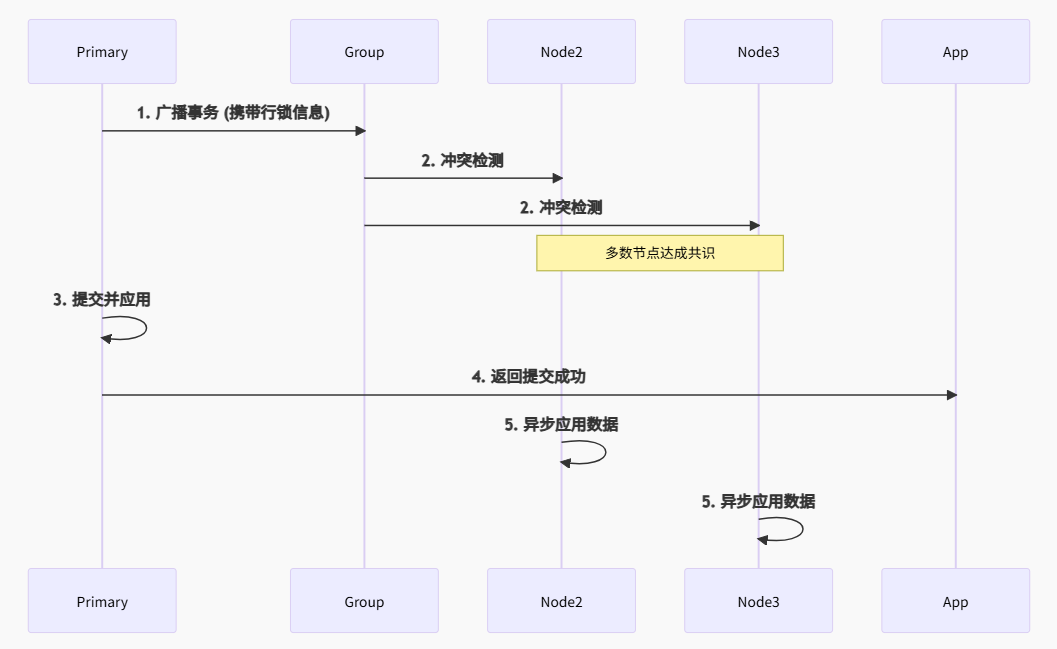
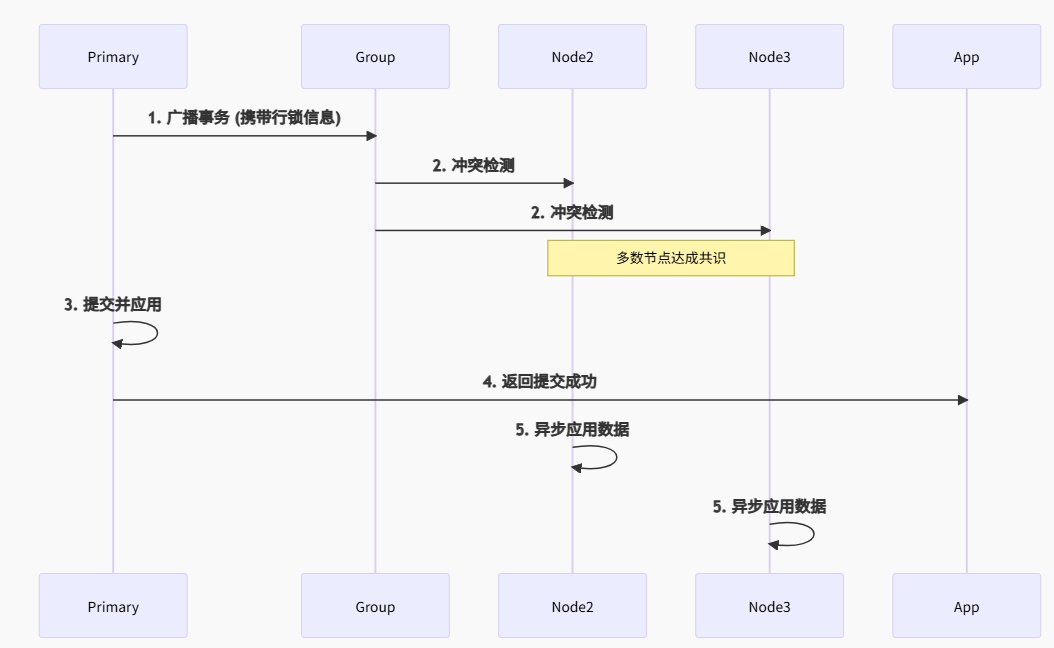
3.1.3 MGR
特点:
强一致性:事务提交需多数节点认证
零数据丢失:返回成功 = 数据在多数节点持久化
自动冲突解决:行级冲突检测 (certification)
3.1.4 决策
搭建主从节点方式是局域网,局域网一般网络延迟小于5ms。(当然这里需要验证和测试) 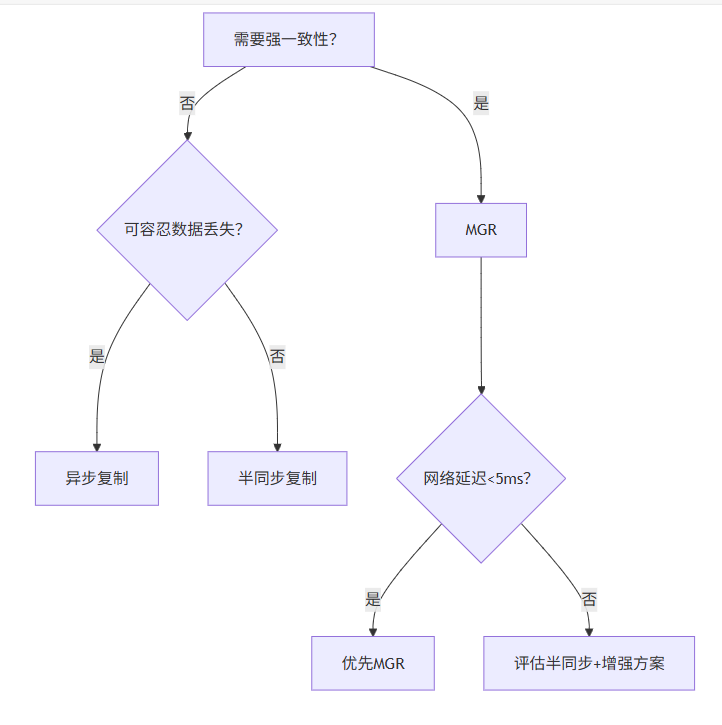
四、安装
最终采用组复制+Router,请参考下面官方文档:
Mysql Group Replication 官网安装步骤 Mysql Router 插件 官网安装步骤
等等…… 我既然选择了MGR+Router,为啥不选择 InnoDB Cluster呢?
五、Mysql官方方案比较
上面提到的MHA已经在不维护了,那还得看其他的解决方案,这边整理了官方以下方案:
- 主从半同步复制、
- InnoDB ReplicaSet、
- 组复制(MGR)、
- InnoDB Cluster、
- InnoDB ClusterSet
5.1. 主从半同步复制
(Semi-Synchronous Replication)
-
原理:主库提交事务前需至少一个从库确认接收Binlog,超时自动降级为异步复制
-
优势:
✅ 数据丢失风险低于异步复制(如支付流水日志)
✅ 成本低(2节点即可部署) -
局限:
❌ 切换时可能丢失超时窗口内的数据(默认10秒)
❌ 需配合Keepalived等工具实现VIP漂移 -
典型场景:
-
电商订单查询系统(读多写少)
-
制造业MES实时数据采集2
-
5.2. InnoDB ReplicaSet
-
原理:基于异步复制的自动化管理套件(MySQL Shell + Router),简化主从配置9
-
优势:
✅ 分钟级部署(自动配置复制账号、GTID)
✅ 支持Router自动读写分离 -
局限:
❌ 无自动故障切换(需手动提升主节点)
❌ 数据一致性弱(依赖异步复制) -
典型场景:
-
中小型企业内部管理系统(OA、CRM)
-
开发测试环境高可用模拟
-
5.3. 组复制
(MGR, MySQL Group Replication)
-
原理:基于Paxos协议的多节点共识,事务需多数节点(N/2+1)认证后提交410
-
优势:
✅ 强一致性(金融级数据安全,如账户余额)
✅ 自动选主与节点自愈(无需外部工具) -
局限:
❌ 仅支持InnoDB表且必须含主键58
❌ 网络延迟>50ms时性能骤降 -
典型场景:
-
支付核心交易系统(RPO=0要求)
-
政务数据共享平台(多部门数据强同步)
-
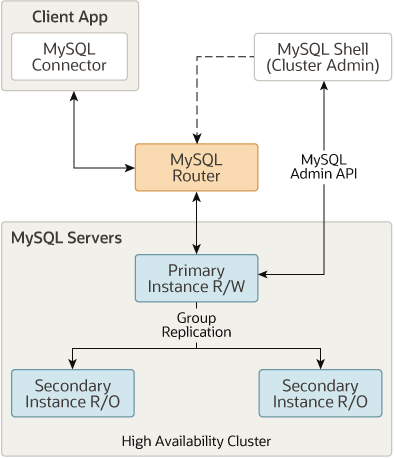
5.4. InnoDB Cluster
-
原理:整合MGR + MySQL Router(流量代理) + MySQL Shell(管理)
-
优势:
✅ 图形化运维(一键扩缩容、故障修复)
✅ 读写分离自动路由(Router隐藏后端拓扑) -
局限:
❌ 绑定MySQL官方生态(版本需严格兼容)
❌ Router需单独部署高可用 -
典型场景:
-
云数据库服务(如AWS RDS高可用版)
-
大型ERP系统(多模块数据强一致)
-
5.5. InnoDB ClusterSet
-
原理:多个InnoDB Cluster通过异步复制组成跨地域集群,主Cluster故障时备用Cluster接管9
-
优势:
✅ 地域级容灾(如机房级故障切换)
✅ 备用Cluster可提供只读服务 -
局限:
❌ 跨集群切换需手动触发
❌ 备用集群数据延迟(依赖异步复制) -
典型场景:
-
跨国电商全球业务(多活地域部署)
-
金融行业两地三中心容灾架构
-
如果对你有帮助,点个收藏⭐,点个赞![]() 再去官方盘文档呗……
再去官方盘文档呗……
--------------------------------------------结束--------------------------------------------
扩展阅读

